
NoisyTune: A Little Noise Can Help You Finetune
Type: Paper
Intro
-
What is the name of the NoisyTune paper?
NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better
Chuhan Wu† Fangzhao Wu‡ Tao Qi† Yongfeng Huang† Xing Xie‡, Tsinghua University
-
NoisyTune shows that adding
random noiseto the parameters of a pretrained language model can improve performance after finetuning -
The motivation for adding noise in NoisyTune is to
reduce overfitting- Idea is that parameters may be overfitted to the self-supervised pretraining tasks
Method
- NoisyTune noise depends on the
parameters of the weight matrix- noise is uniform, range depends on standard deviation of weight matrix
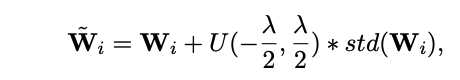
- $\lambda$ is a hyperparameter controlling amount of noise
That is the entire idea of this very simple method
Results
-
The NoisyTune method leads to
consistentgains across different models and GLUE tasks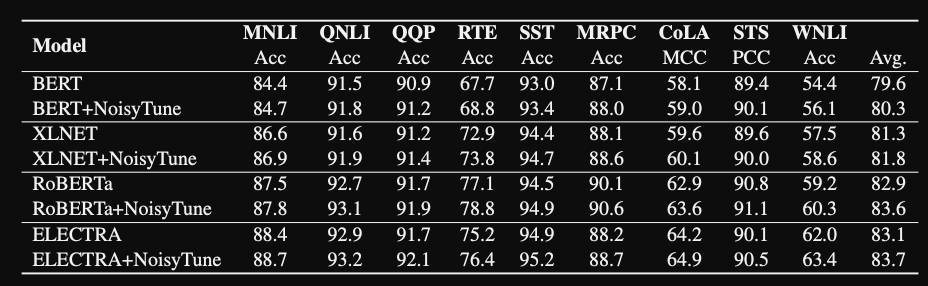
- They report similar small gains on the XTREME multilingual benchmark
-
NoisyTune: during finetuning parameters make smaller L1 updates suggesting that
standard finetuning has to overcome more overfitting to training set- Note: This reasoning is more of a theory than a proven mechanism
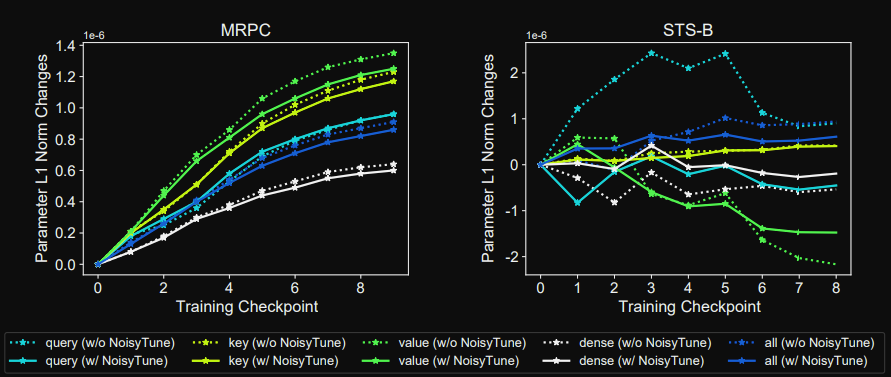
Conclusions
The NoisyTune methods is a simple extension that seemingly provides robust performance transfer to downstream tasks. Adding noise could easily be applied to any language model of interest although I would like to see experiments on some larger models. The theoretical motivation might be similar to dropout but needs further study. They find that $\lambda = 0.15$ performs well across datasets suggesting a standard level of noise to apply. As a regularization method for finetuning it is much simpler to implement than Microsoft’s SMART and thus has more potential to augment the standard finetuning paradigm.
Reference
@article{wu2022noisytune,
title={NoisyTune: A Little Noise Can Help You Finetune Pretrained Language
Models Better },
author={Chuhan Wu and Fangzhao Wu and Tao Qi and Yongfeng Huang and Xing Xie },
year={2022},
journal={arXiv preprint arXiv: Arxiv-2202.12024}
}