
PromptBERT improving BERT sentence embeddings with prompts
Intro
The PromptBERT paper combines two recent major streams of research, namely prompting and sentence embeddings. Sentence embeddings are important because converting a sentence to a dense embedding can allow for efficient semantic text search. The authors note that the naive sentence embeddings generated by the original BERT model perform rather poorly. By applying prompts in an unsupervised contrastive pretraining phase and by leveraging a new template denoising technique they achieve better performance than previous sentence embedding methods.
-
What is the name of the PromptBERT paper?
PromptBERT: Improving BERT Sentence Embeddings with Prompts
-
The contributions of the promptBERT paper are primarily a
prompt based sentence embedding method that outperforms SIMCSE- They design methods for generating prompts
- They apply template denoising in the unsupervised pretraining objective
Method
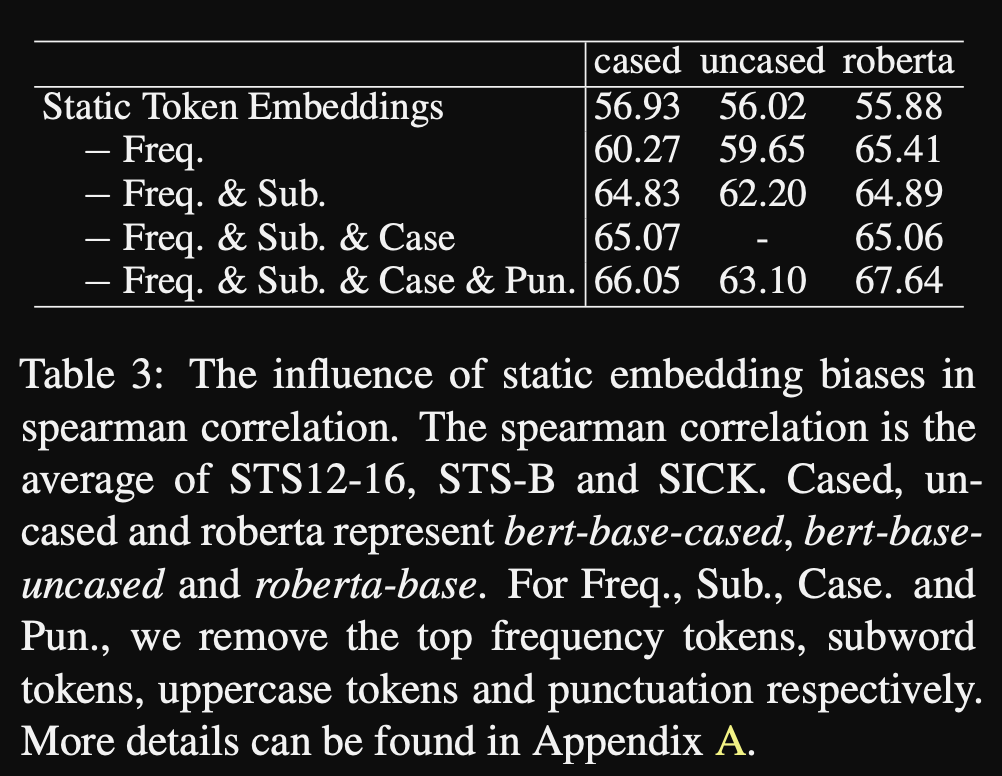
- In promptBERT the identify token bias as a problem:
bias caused by high frequency tokens- they claim that this is unrelated to the ansiotropy problem
- they show that removing high frequency tokens helps the performance of static embeddings
- promptBERT prompts a model to generate sentence embeddings using a
template with a mask token- For example embedding sentence [X] we would prompt the model with the template “[X] means [MASK]”
- There are two methods to extract the sentence embedding
- use the hidden state of the mask token
- average the static embeddings of the top k tokens predicted by the MLM
- They find the first method easier to use in practice
-
promptBERT greedy search for optimal prompts gets best prompt as
This sentence [X] means mask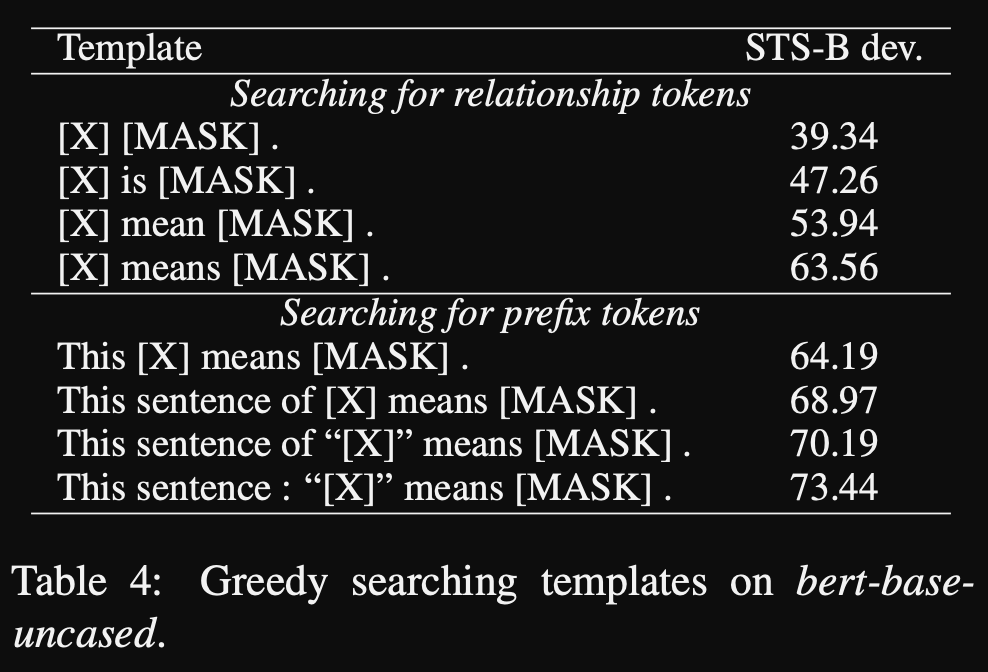
- promptBERT generates prompts through three methods:
1) Manual 2) T5 generation and 3) OPTIPROMPT- T5 generation follows the method from the LMBFF paper
- Best prompt found was “Also called [MASK]”
- Optiprompt trains prompt token embeddings in the continuous space
- Still initialize from embeddings of manual prompts
- performed best overall
- T5 generation follows the method from the LMBFF paper
- The promptBERT contrastive training objective leverages representations from
two different prompt templatesas positive pairs- Alternative to the dropout mask used in SIMCSE
- They also apply a template denoising technique
- Template debiasing in promptBERT subtracts off the
BERT representation of the template with consistent positional encodings- For example if we use the template “[X] means [MASK]” we would subtract the BERT representation of “means” with shifted positional encoding from the representation of the MASK token
-
The final unsupervised contrastive training objective is:
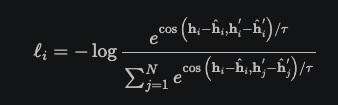
- Contrast against negative samples
- note: only one template will be used at inference time
Results
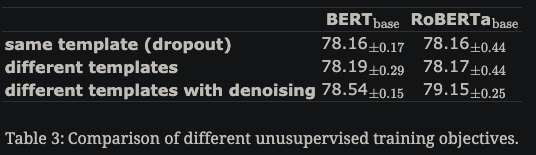
- promptBERT using the same template and applying inner dropout gives
slightly worse performance- compare to a basic extension of SIMCSE
- adding denoising helps slightly
- promptBERT achieves SOTA on STS tasks
- base BERT model
- do they train a single continuous prompt for all tasks?
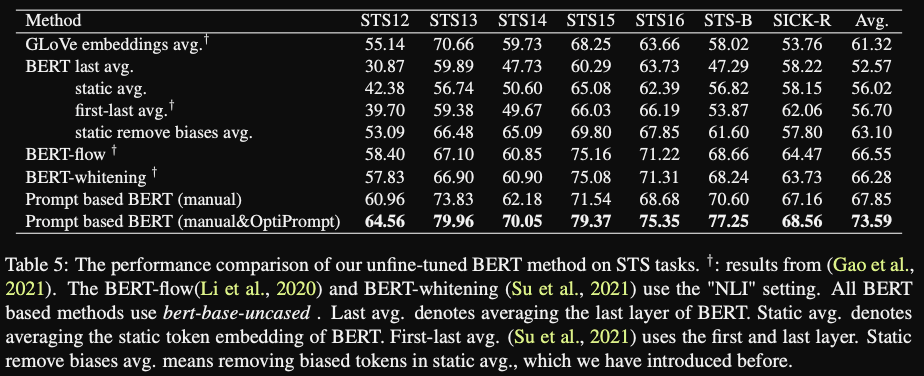
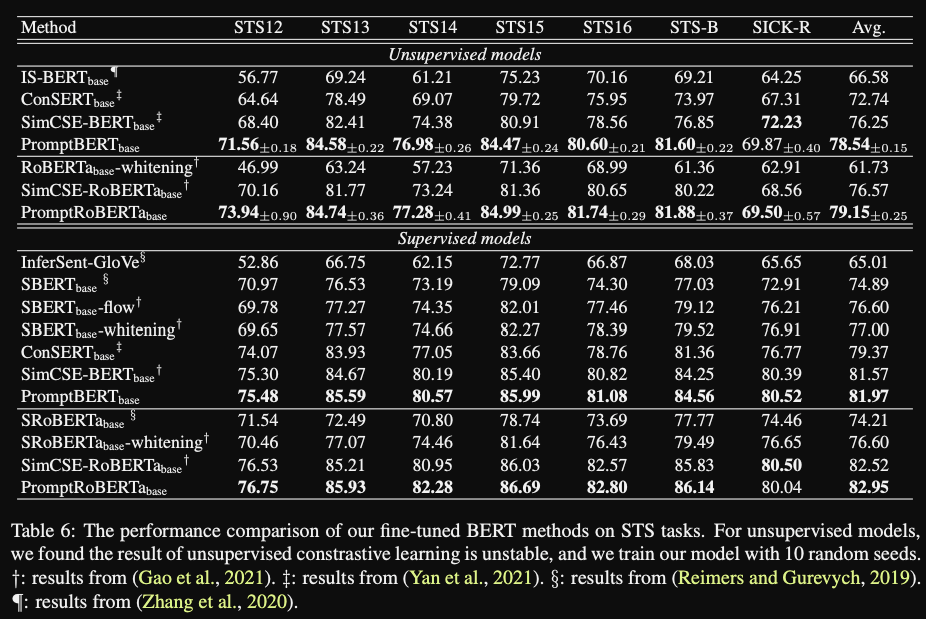
- promptBERT finetuning for STS tasks gives
even better results- Do they apply normal finetuning on the [MASK] token representations?
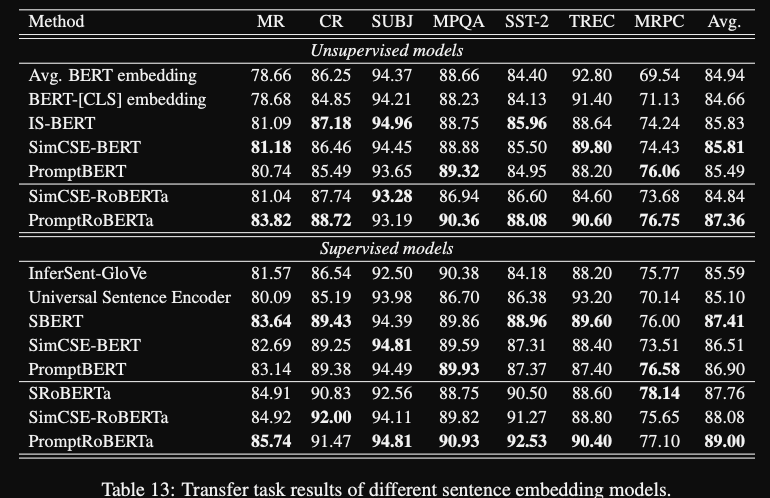
- promptBERT also achieves very good supervised and unsupervised results on GLUE
- unsupervised results are sentEVAL style evaluation
Conclusion
This paper runs a set of basic experiments applying the prompting paradigm to sentence embeddings. The results consistently outperform other sentence embedding techniques such as SBERT and SIMCSE. Applying the template denoising is a simple trick that seems to help. It would be interesting to see theoretical analysis on what information is contained in the trained prompt. Another extension would be to evaluate if prompts can be trained while freezing the rest of the language model parameters in order to allow for a plug in approach to improve sentence embeddings of existing models. It would be interesting to add in comparisons to the supervised pretraining that SBERT performs on NLLI. Theoretically prompts could also help guide the representations of positive pairs from NLI.The strong supervised results on GLUE suggest that a workflow of MLM pretraining → unsupervised sentence embedding pretraining → supervised finetuning could become a standard approach for text classification tasks.
Reference
@misc{jiang2022promptbert,
title={PromptBERT: Improving BERT Sentence Embeddings with Prompts},
author={Ting Jiang and Shaohan Huang and Zihan Zhang and Deqing Wang and Fuzhen Zhuang and Furu Wei and Haizhen Huang and Liangjie Zhang and Qi Zhang},
year={2022},
eprint={2201.04337},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Code
https://github.com/kongds/Prompt-BERT