
Capturing Failures of Large Language Models via Human Cognitive Biases
Intro
-
What is the name of the UCB human cognitive biases paper
Capturing Failures of Large Language Models via Human Cognitive Biases
Erik Jones, Jacob Steinhardt UC Berkeley
The main idea of this paper is to evaluate failures of large language models using methods inspired from human cognitive biases. Human cognitive biases are known phenomena where people make erroneous or irrational judgement.
- What are the main contributions of the UCB cognitive biases paper?
- Use four cognitive biases to identify errors made by GPT-Codex
- errors based on framing of prompt
- errors based on anchors
- bias based on training set frequencies
- reversion to simpler problems
- Use four cognitive biases to identify errors made by GPT-Codex
- Human cognitive biases were famously identified by Tversky and Kahneman
There are many examples of human cognitive biases. For example:
Pareidoliais the tendency for perception to impose a meaningful interpretation on a nebulous stimulus usually visual, so that one sees an object, pattern, or meaning where there is none.- Why do the authors choose to focus on code generation as an evaluation task?
- objectivity the generated code output is either correct or not
- open ended there are many way to solve the same problem
Method
The authors use a simple setup to evaluate the GPT-Codex model
- The authors probe 4 main cognitive biases in the GPT-Codex model
- Framing Effect
- Anchoring Effect
- Availability Heuristic
- Attribute substitution
- The authors probe the impact of the framing effect on code generation by
prepending an irrelevant function prompt and a framing line to the prompt- The use
raise NotImplementedError,pass,assert False,return False, andprint("Hello world!")as framing lines

- In this example the model erroneously generates the framing line instead of the correct answer
- The use
-
For the anchoring effect the authors test the model be prepending a related but
inccorectanchor function to the prompt
- In the example, the model fails to adjust and gets distracted by the anchor function
-
The authors test the availability heuristic by testing when codex fails to
give the correct order of operations
- The function needs to sum the inputs first, then square
- In GPT codex one can test the attribute substitution bias by giving a prompt along with a
misleading function name- tends to follow the function name

Results
The paper results show that the model is very susceptible to the cognitive biases of the tasks that they construct.
- GPT codex: framing bias results: adding framing leads to
huge drop in accuracy- large tendency to copy
passstatement
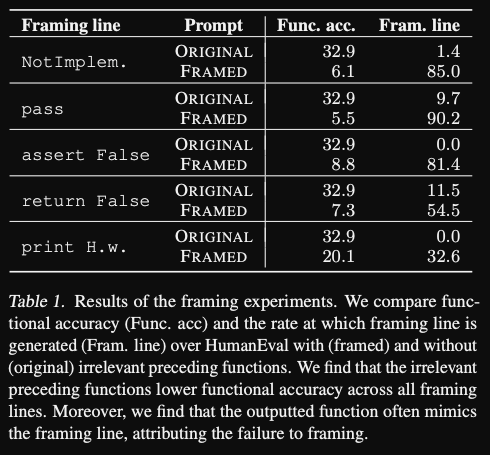
- large tendency to copy
-
GPT codex: anchoring with
irrelevant statementsleads to drop in performance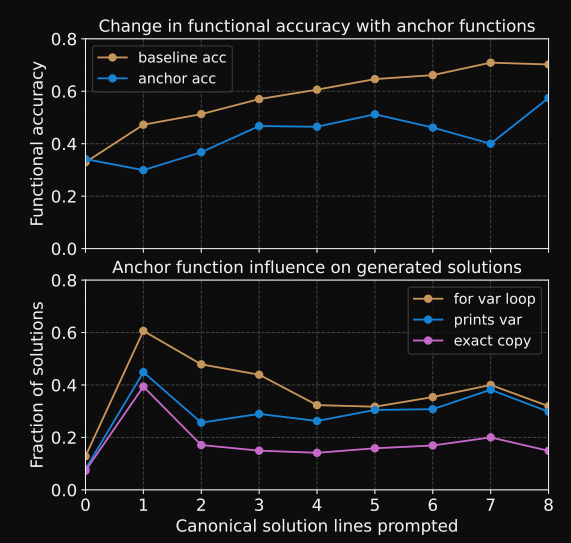
- the model also tends to erroneously copy these anchors
- The availability heuristic
- 24 combinations and orderings of the binary operations sum, difference, and product, with unary operations square, cube, quadruple, and square root
- Only generates output correctly for 9/24
-
Attribute substitution bias adding misleading function signatures leads to
huge drop in accuracy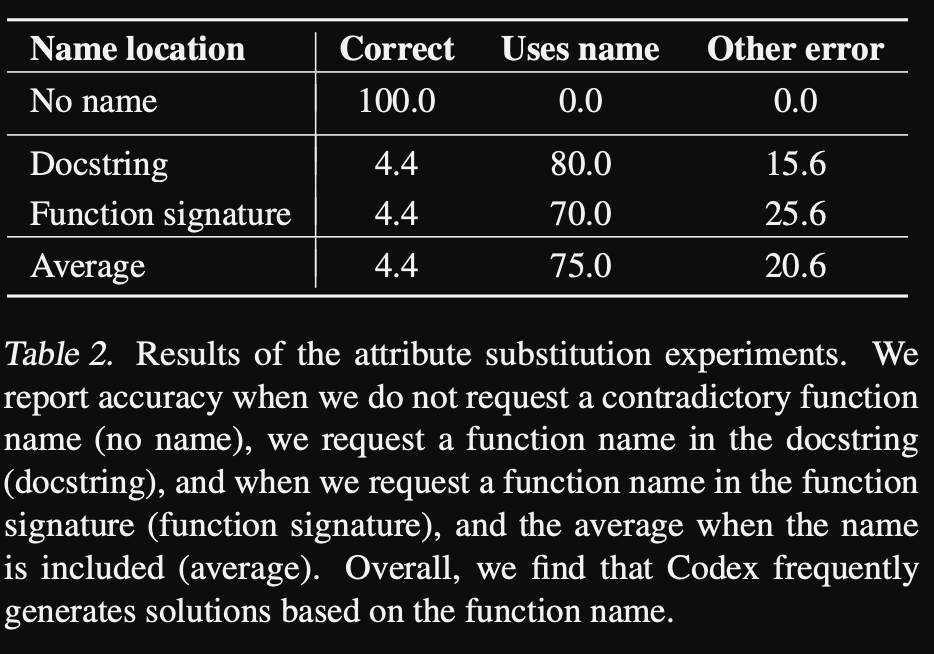
They also evaluate how GPT3 performs with respect to the anchoring bias
- Probing GPT3 for anchoring bias
- Can anchor the model to a higher or lower value

- Results: output is very often affected by anchoring biase
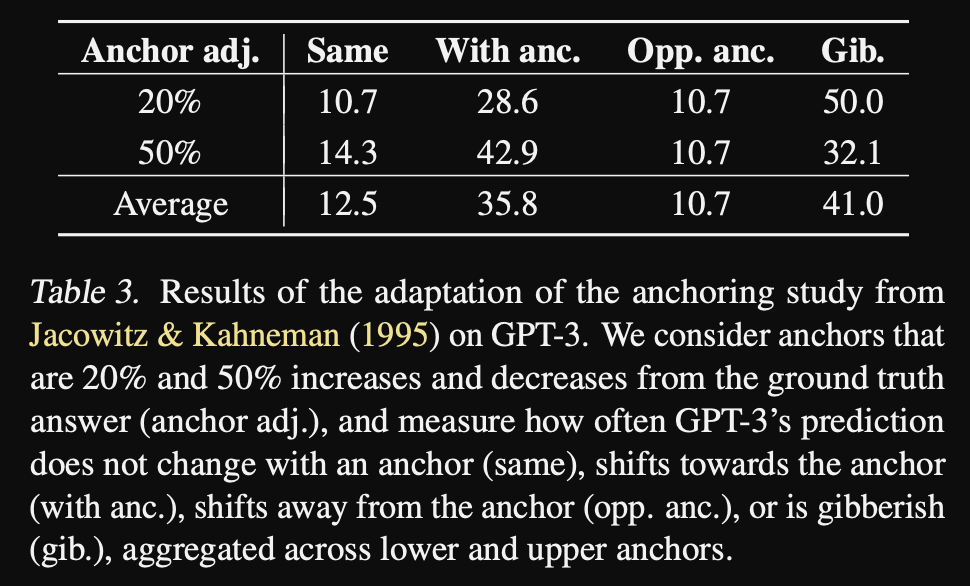
Conclusions
Overall there is a little bit of a mismatch between the probing tasks and the precise definition of the cognitive bias. For example, the attribute substitution task could really be called a ignore the misleading function name or deal with conflicting prompt task and does not actually probe any fundamental tendency of the model to respond to a simpler question. Additionally, many other probing tasks could be designed for the availability heuristic. Overall the paper could be framed more as an exploration of how GPT codex deals with different prompts. However the approach of drawing inspiration from human cognitive biases is very interesting and can hopefully be applied to other language models.
Reference
@article{jones2022capturing,
title={Capturing Failures of Large Language Models via Human Cognitive Biases },
author={Erik Jones and Jacob Steinhardt },
year={2022},
journal={arXiv preprint arXiv: Arxiv-2202.12299}
}