
Universal Sentence Representation Learning with Conditional Masked Language Model
Introduction
-
What is the name of the CMLM paper?
Universal Sentence Representation Learning with Conditional Masked Language Model
- What are the main contributions of the CMLM paper?
- unsupervised sentence embedding method that beat SBERT
- strong multilingual performance
- CMLM is significant because it is the base model for
Spotify's neural search- Do they use it because it is good or because it supports cross lingual queries
Method
- CMLM is stated to be similar to
skipthought and T5 methods- MLM rather than regenerating whole sentence
- idea of conditioning on a dense sentence representation is extended in DIFFCSE paper
-
The basic idea behind CMLM is to condition a MLM on
dense vector representation of previous sentence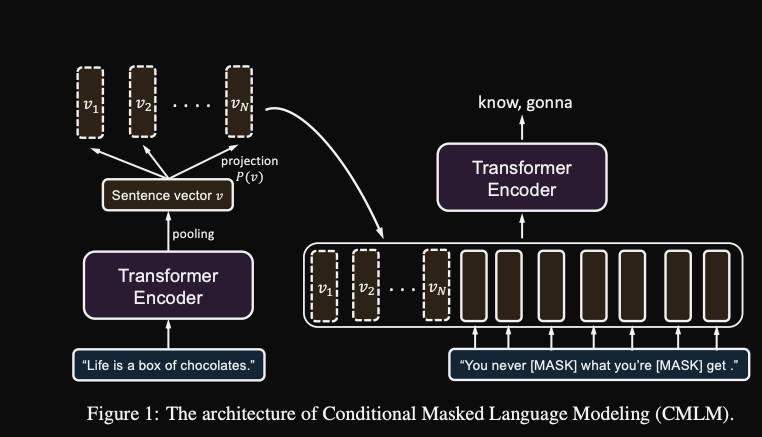
Results
-
CMLM senteval results: beats
SBERT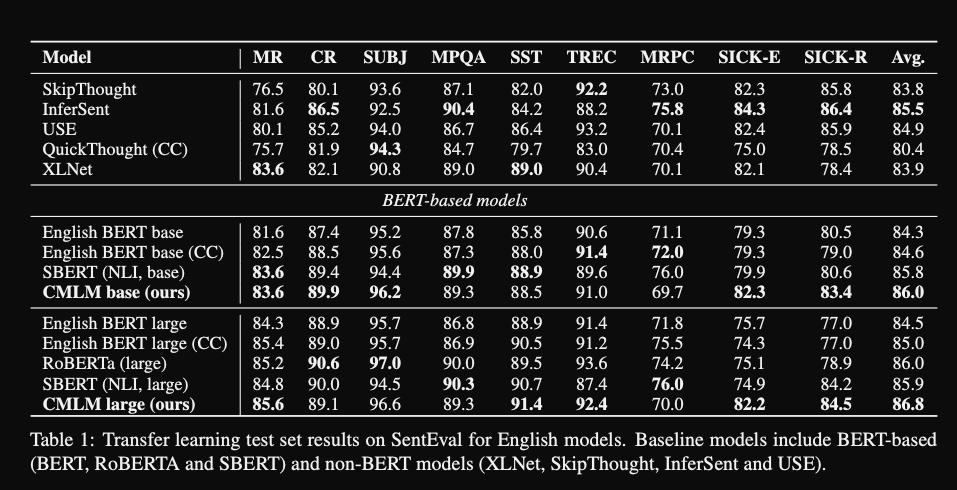
-
CMLM multilingual semantic search results strong performance across
30/36 languages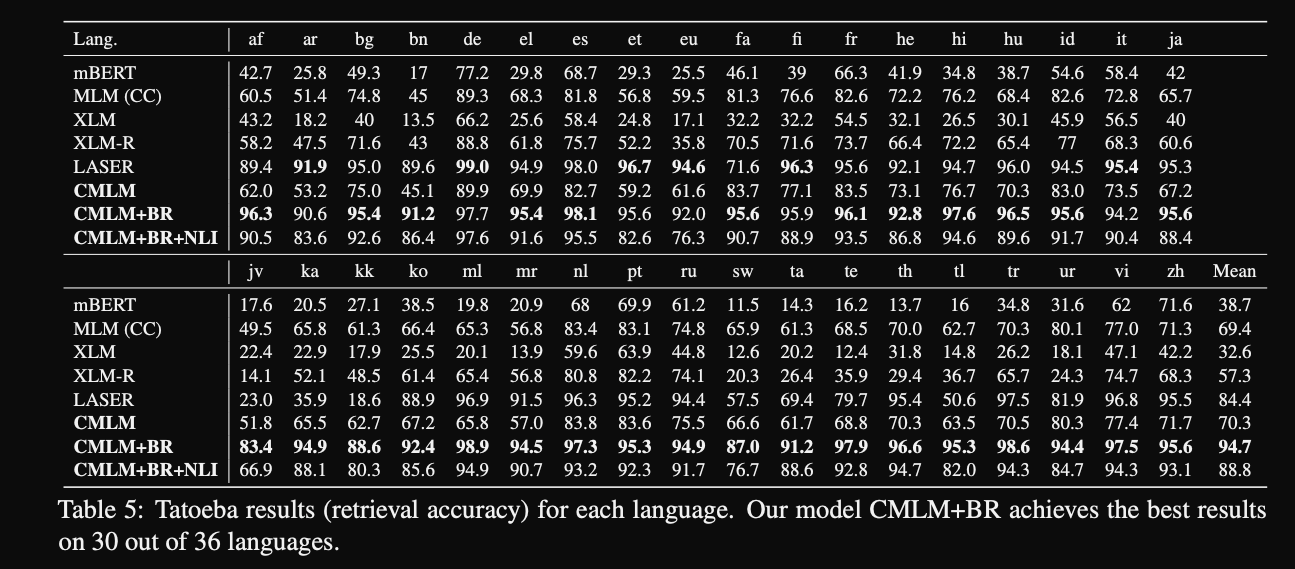
Conclusions
Why would Spotify use a model from early 2021 for their semantic search. I believe the answer lies in the strong multilingual semantic search performance. Other unsupervised embedding methods may not train or evaluate on multilingual datasets and thus may not be able to be directly compared.
Reference
@article{yang2020universal,
title = {Universal Sentence Representation Learning with Conditional Masked Language Model},
author = {Ziyi Yang and Yinfei Yang and Daniel Cer and Jax Law and Eric Darve},
year = {2020},
journal = {arXiv preprint arXiv: Arxiv-2012.14388}
}