
PALM
Introduction
-
What is the name of the PALM paper?
PaLM: Scaling Language Modeling with Pathways
Method
-
PALM was trained on
780 billion tokens of high-quality text - Pathways is google’s
scaling infrastructure for TPUs- train PALM on 6144 TPU v4 chips
-
PALM scaling laws show
lack of approaching saturation point - PALM breakthrough capabilities: better results on
reasoning tasks- combine with chain of thought prompting
- PALM exhibits discontinuous improvements on
25% of big bench tasks- large jumps in performance from 62B to 540 B parameters
-
PALM has strong multilingual performance with
22% non english training data - Main PALM architectural advancements:
- SwiGLU activation
- outperform ReLU in compute equivalent experiments
- Parallel layers
- run attention and MLP computation in parallel
- Multiquery attention
- share key and value projections for each head
- SwiGLU activation
-
PALM multiquery attention leads to
cost savings during autoregressive decoding - PALM uses Shared
Input-Output Embeddings- used in some transformer architectures
-
Plurality of PALM training data comes from
social media conversations
- Megatron-Turing NLG 530B (Smith et al.,
2022) was trained on
2240 A100 GPUs -
PALM sequence length is
2048 -
PaLM is finetunedwith 5 × 10−5 learning rate using the Adafactor optimizer, with a batch size of 32. PaLM converges typically in less than
15K steps of finetuning -
PALM bigbench results: SOTA on
most tasks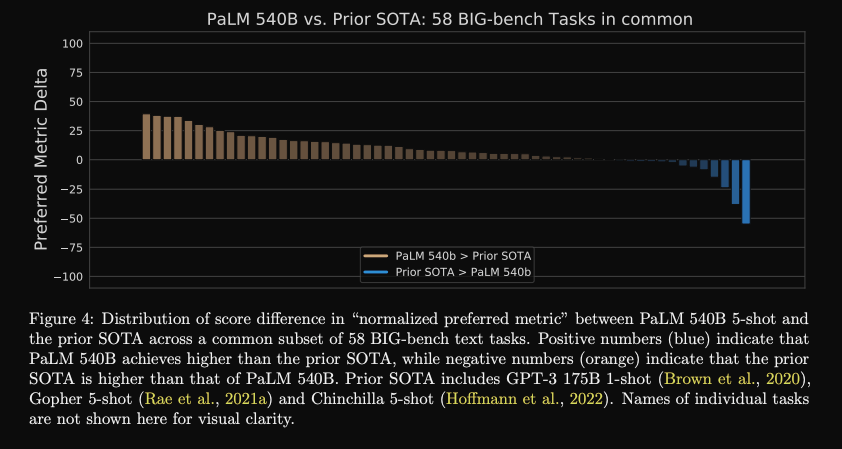
-
Multistep reasoning categories include
arithmetic and commonsense reasoning - Chain of thought prompting adds
step by step examples to in context prompts- model will generates its reasoning before generating the final answer

Results
-
PALM evaluates language model memorization by
prompting with 50/100 tokens of training text and greedy decoding -
PALM memorization results: large model
memorizes more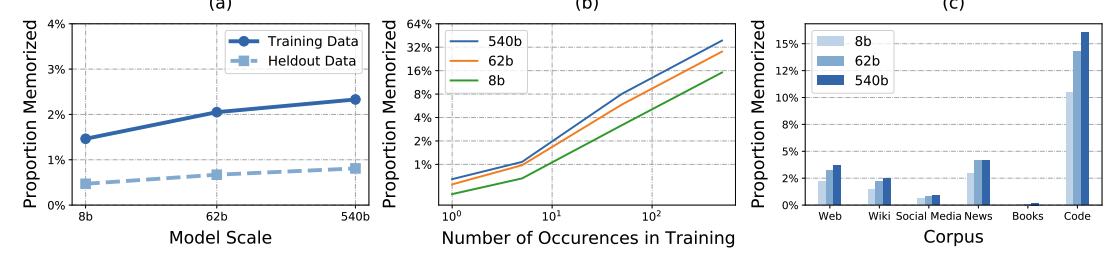
-
PALM explanation experiments use
two shot exemplars- followed by greedy decoding
- example: joke explanation

Reference
@misc{https://doi.org/10.48550/arxiv.2204.02311,
doi = {10.48550/ARXIV.2204.02311},
url = {https://arxiv.org/abs/2204.02311},
author = {Chowdhery, Aakanksha and Narang, Sharan and Devlin, Jacob and Bosma, Maarten and Mishra, Gaurav and Roberts, Adam and Barham, Paul and Chung, Hyung Won and Sutton, Charles and Gehrmann, Sebastian and Schuh, Parker and Shi, Kensen and Tsvyashchenko, Sasha and Maynez, Joshua and Rao, Abhishek and Barnes, Parker and Tay, Yi and Shazeer, Noam and Prabhakaran, Vinodkumar and Reif, Emily and Du, Nan and Hutchinson, Ben and Pope, Reiner and Bradbury, James and Austin, Jacob and Isard, Michael and Gur-Ari, Guy and Yin, Pengcheng and Duke, Toju and Levskaya, Anselm and Ghemawat, Sanjay and Dev, Sunipa and Michalewski, Henryk and Garcia, Xavier and Misra, Vedant and Robinson, Kevin and Fedus, Liam and Zhou, Denny and Ippolito, Daphne and Luan, David and Lim, Hyeontaek and Zoph, Barret and Spiridonov, Alexander and Sepassi, Ryan and Dohan, David and Agrawal, Shivani and Omernick, Mark and Dai, Andrew M. and Pillai, Thanumalayan Sankaranarayana and Pellat, Marie and Lewkowycz, Aitor and Moreira, Erica and Child, Rewon and Polozov, Oleksandr and Lee, Katherine and Zhou, Zongwei and Wang, Xuezhi and Saeta, Brennan and Diaz, Mark and Firat, Orhan and Catasta, Michele and Wei, Jason and Meier-Hellstern, Kathy and Eck, Douglas and Dean, Jeff and Petrov, Slav and Fiedel, Noah},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {PaLM: Scaling Language Modeling with Pathways},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}