
Task-guided Disentangled Tuning for Pretrained Language Models
Introduction
-
What is the name of the TDT paper?
Task-guided Disentangled Tuning for Pretrained Language Models
- What are the main contributions of the tdt paper?
- Learn confidence scores for input tokens
- Learn more generalized features
- Captures the high confidence cues for downstream tasks
- A problem with finetuning PLM is that they may learn to rely on
spurious correlations- May not generalize well
- How can we get them to learn more robust features

- The core of the TDT method is a
confidence scorefor input tokens
Method
-
The token level confidence model in TDT is a learned
linear transform of embedding layer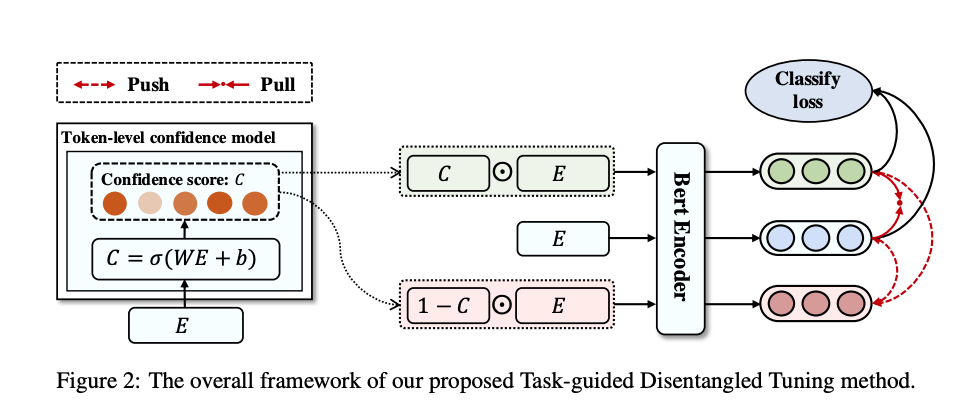
-
TDT generates a distilled input which is
perturbed more for low confidence tokens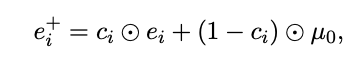
- The TDT classification model loss is trained to
maximize the task classification performance- regularization penalty to prevent mode collapse
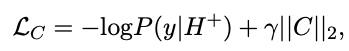
- TDT additionally includes triplet loss with negative samples mined by
taking input embeddings with low confidence - TDT triplet loss optimizes
KL divergence between prediction output distributions of positive and negative instances -
TDT training objective combines
3loss terms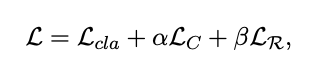
Results
- TDT achieves superior results to
finetuningon GLUE - How does TDT demonstrate superior OOD generalization?
- finetune on MNLI and measure performance on other MNLI tasks
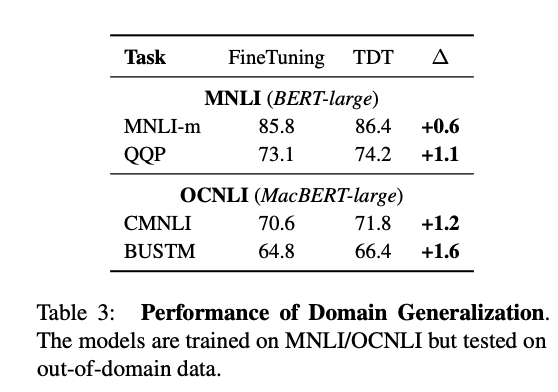
- What are some related methods to TDT?
- Token Cutoff
- R-drop
- R3F
- Post Training
-
R-drop seeks to regularize networks by minimizing divergence of output distribution of an input
passed through a model with two different dropout masks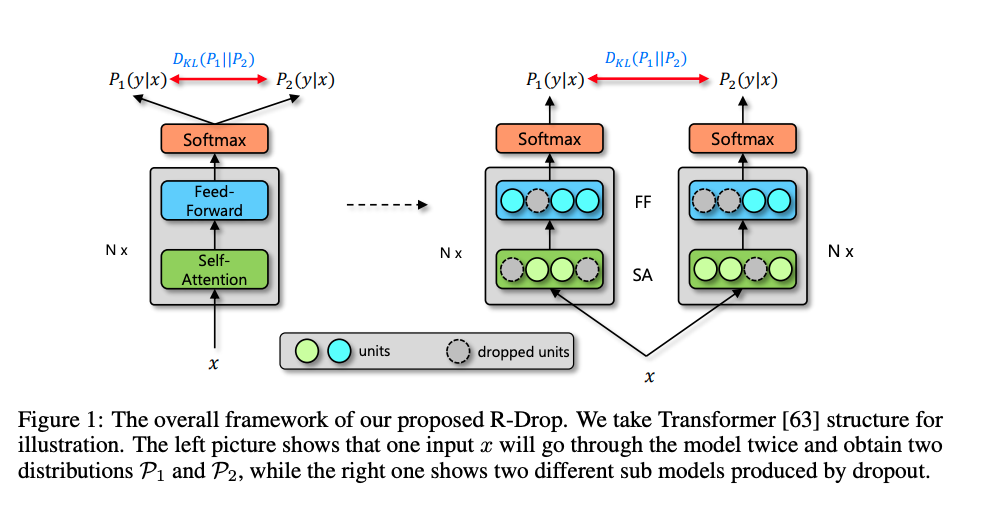
Conclusions
TDT adds an extension to standard finetuning which seeks to promote a model to learn generalizable features. One advantage is that the confidence model is highly interpretable and should give nice insight into which tokens are important for a model prediction. It is related to other techniques that seek to extend the regular finetuning paradigm such as SMART and R-DROP.
Reference
@misc{https://doi.org/10.48550/arxiv.2203.11431,
doi = {10.48550/ARXIV.2203.11431},
url = {https://arxiv.org/abs/2203.11431},
author = {Zeng, Jiali and Jiang, Yufan and Wu, Shuangzhi and Yin, Yongjing and Li, Mu},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Task-guided Disentangled Tuning for Pretrained Language Models},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Non Commercial No Derivatives 4.0 International}
}