
Improving Multi-task Generalization Ability for Neural Text
-
What is the name of the MatchPrompt paper?
Improving Multi-task Generalization Ability for Neural Text Matching via Prompt Learning
- What are the main contributions of the MatchPrompt paper?
- collect datasets of 5 text matching tasks
- specialization generalization training strategy
- train multitask models than can surpass the performance of specialized models
- One hypothesis for poor OOD performance of neural IR models is that different matching tasks rely on
different matching signals- eg: bigram features important for QA
- Text matching tasks can rely on different
text matching signals- PI: Paraphrase identification
- RD: retrieval based dialogue
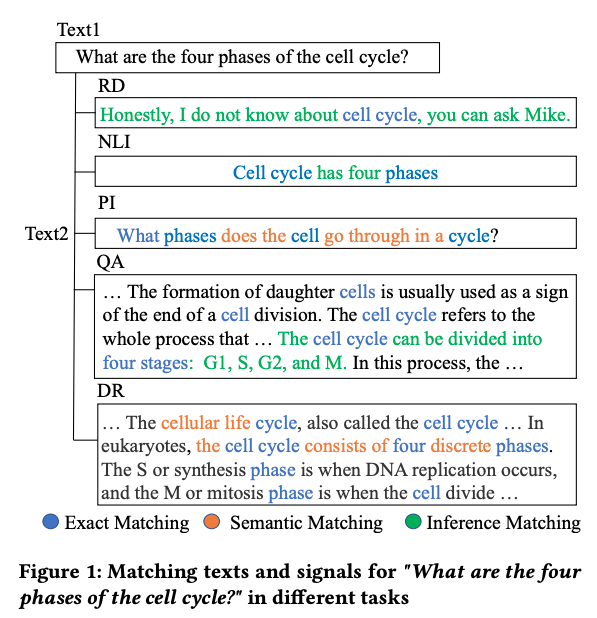
Introduction
Method
-
The matchprompt architecture trains a
separate prompt encoderfor each category of matching task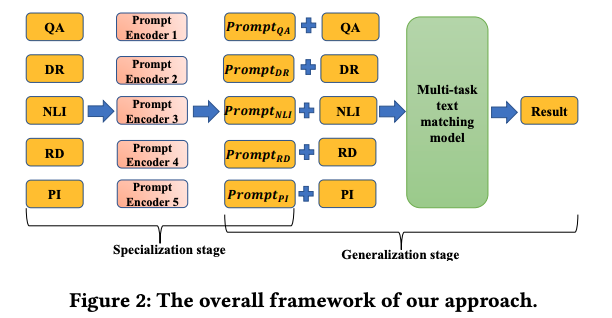
- Match Prompt first trains
category specific promptsand second trains the full BERT layers- similar to 2 stage training approach in the DART paper
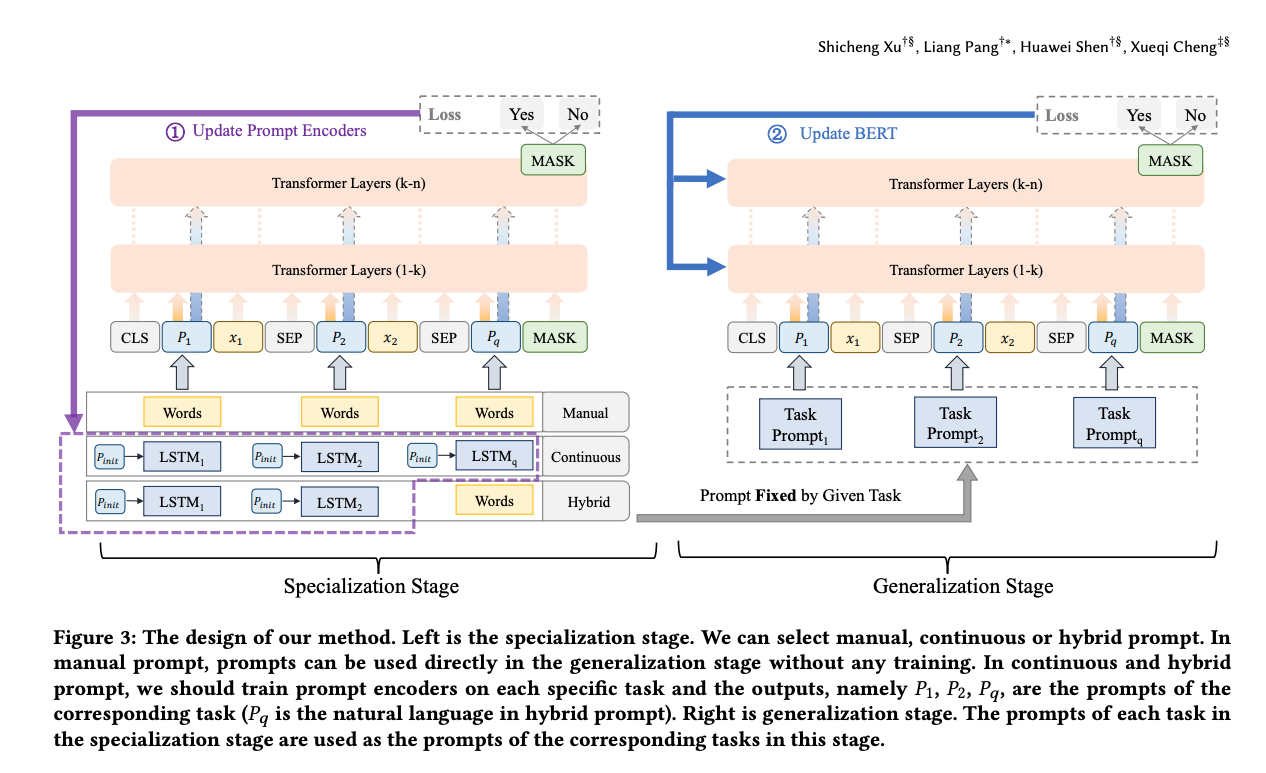
- Match Prompt uses a biencoder with
PET style masked verbalizer- biencoder highly innefficient
- prompts are prepended to each text input
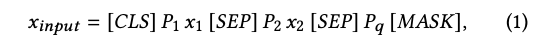
-
MatchPrompt: handcrafted prompts for different task categories:
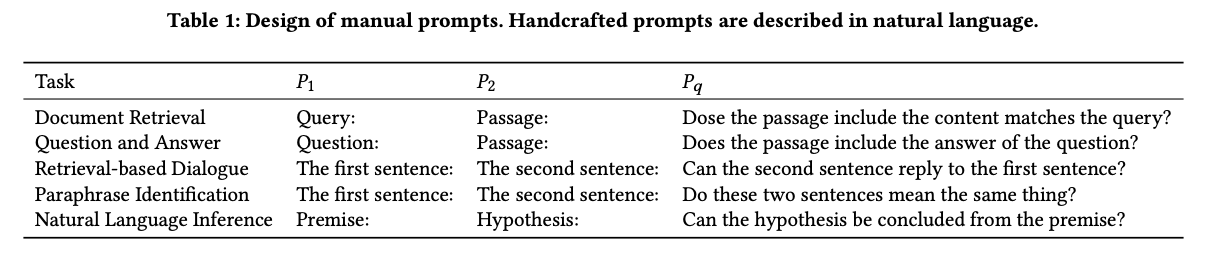
Results
-
MatchPrompt results: hybrid prompt had better
multitask performance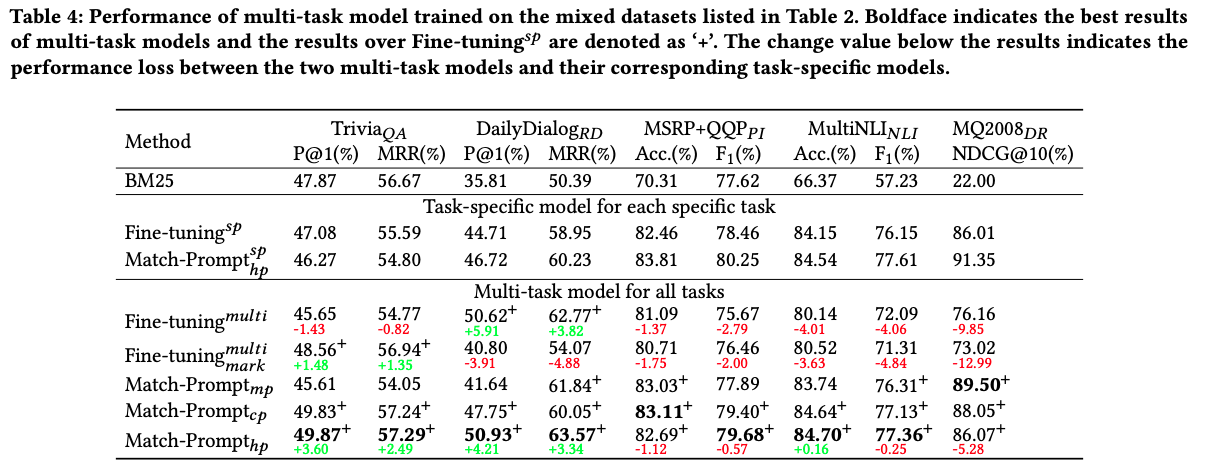
-
MatchPrompt OOD generalization: outperforms
multitask finetuning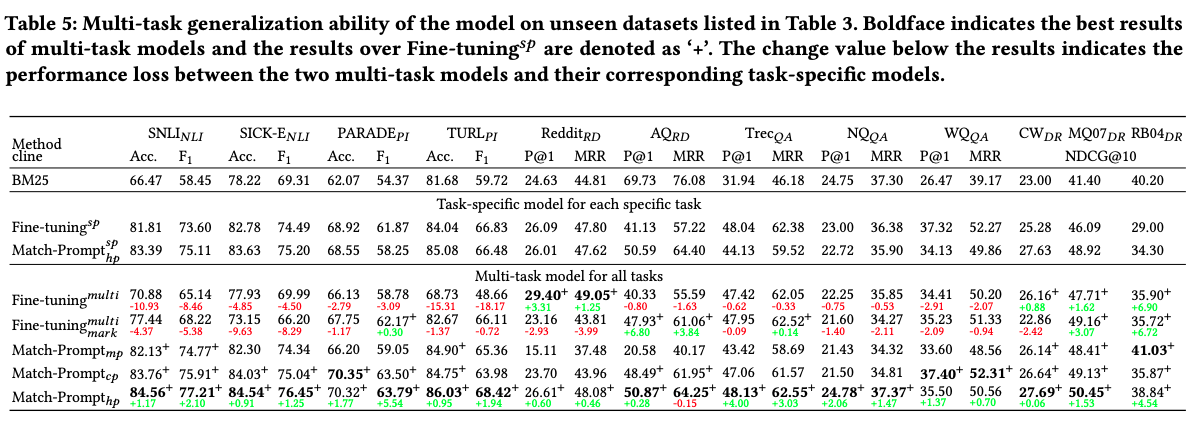
Conclusions
I would like to see some different experiments to explore the power of prompts for more practical information retrieval situations. First, using a biencoder for dense retrieval, rather than a cross encoder. Second training continuous prompts in the style of Lester et al 2021. Third, evaluating on wider sets of IR benchmarks such as MS-MARCO and BEIR would provide better insight into generalization of performance.
Reference
@article{xu2022improving,
title={Improving Multi-task Generalization Ability for Neural Text Matching via Prompt Learning},
author={Xu, Shicheng and Pang, Liang and Shen, Huawei and Cheng, Xueqi},
journal={arXiv preprint arXiv:2204.02725},
year={2022}