
Adaptable Adapters
Introduction
- What are the main contributions of the adaptable adapters paper?
- Adaptable Adapters:
- learning activation functions for different inputs and layers
- learnable switch to use only beneficial adapter layers
- Adapters require less training time and storage space
- using fewer adapters with a learnable activation increases performance in the low data domain
- Adaptable Adapters:
- Padé Activation Units (Molina et al.,
2020), are
learnable activation functionsthat can approximate common activation functions as well as learn new ones. - Rational activation units are parameterized by
twoparameters- order m, n
- a and b are learnable parameters
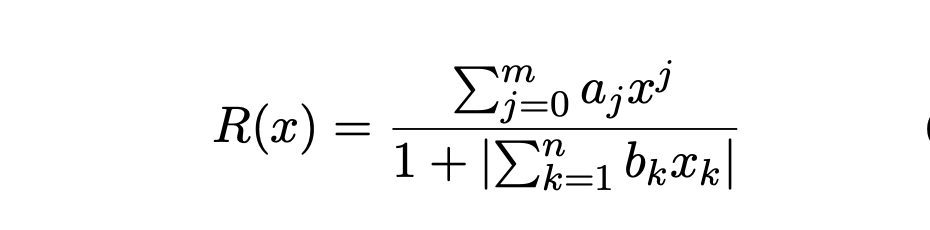
- Schwartz et al. (2020) propose to add an
output layer toeach transformer layer.- confidence based early exiting for efficiency
- AdapterDrop (Rücklé et al., 2021) train adapters with layer dropping and later
drop n layers at inference time
Method
-
Adaptable Adapter layer uses a
rationalactivation function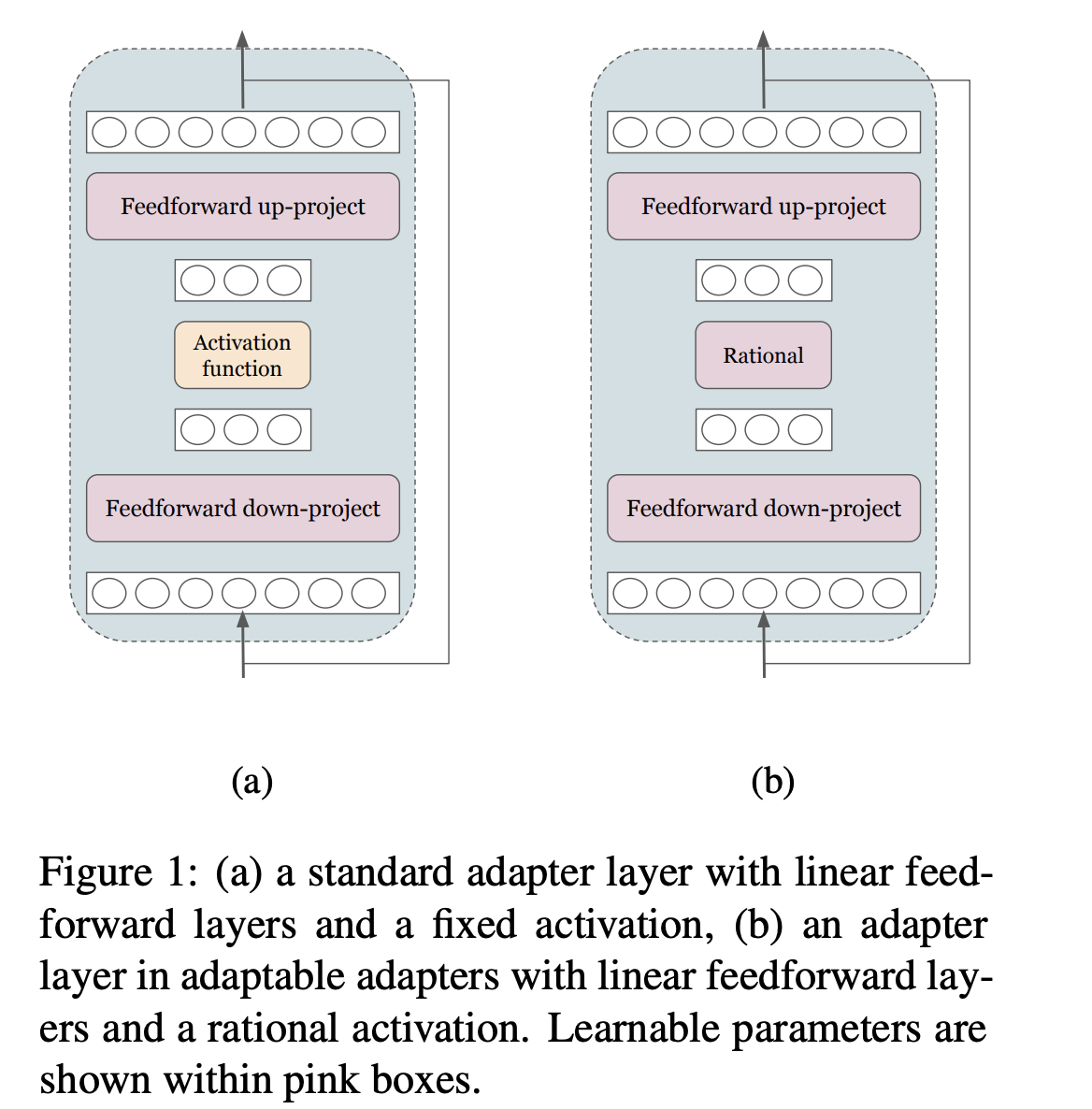
-
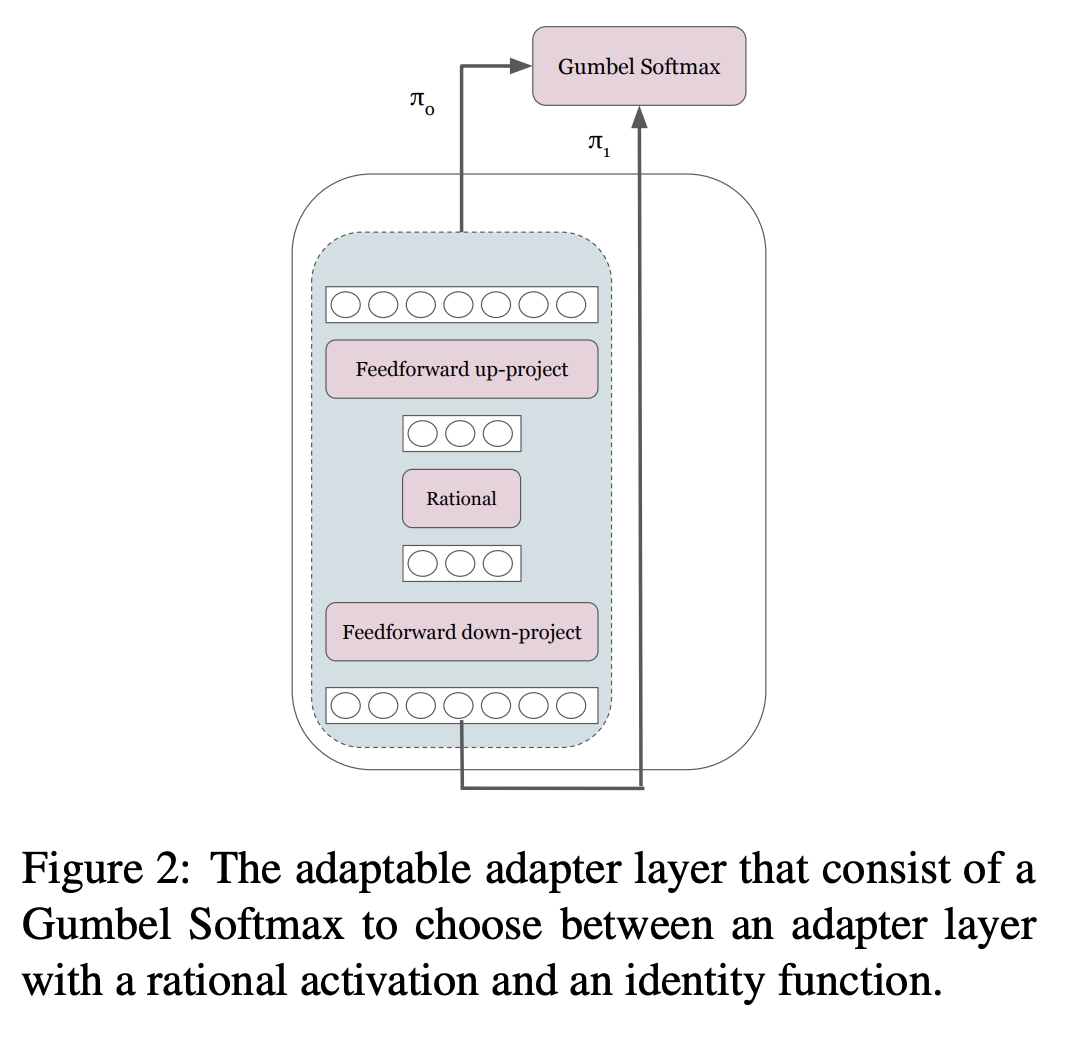
Adaptable adapters uses a
gumbel softmaxto learn when to skip the layer- skipping applied skip connection
Results
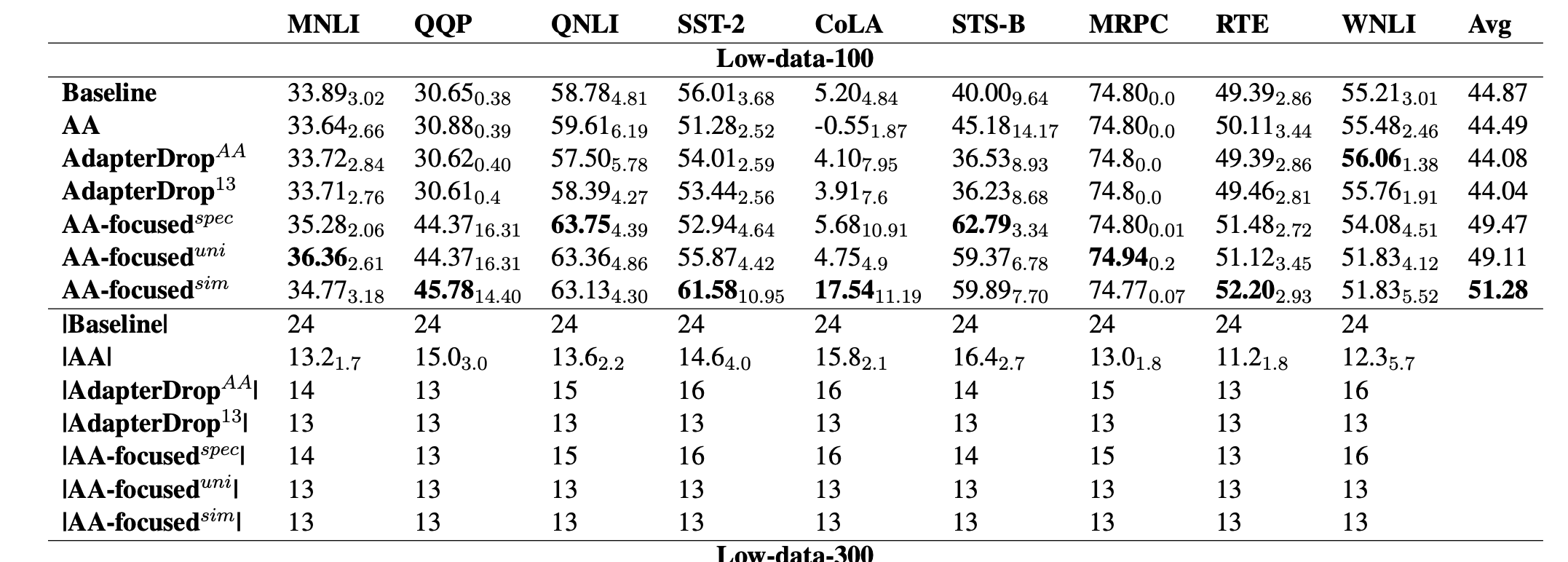
- Adaptive Adapter results: better performance in the
low data regime- adapters are on top of BERT large
-
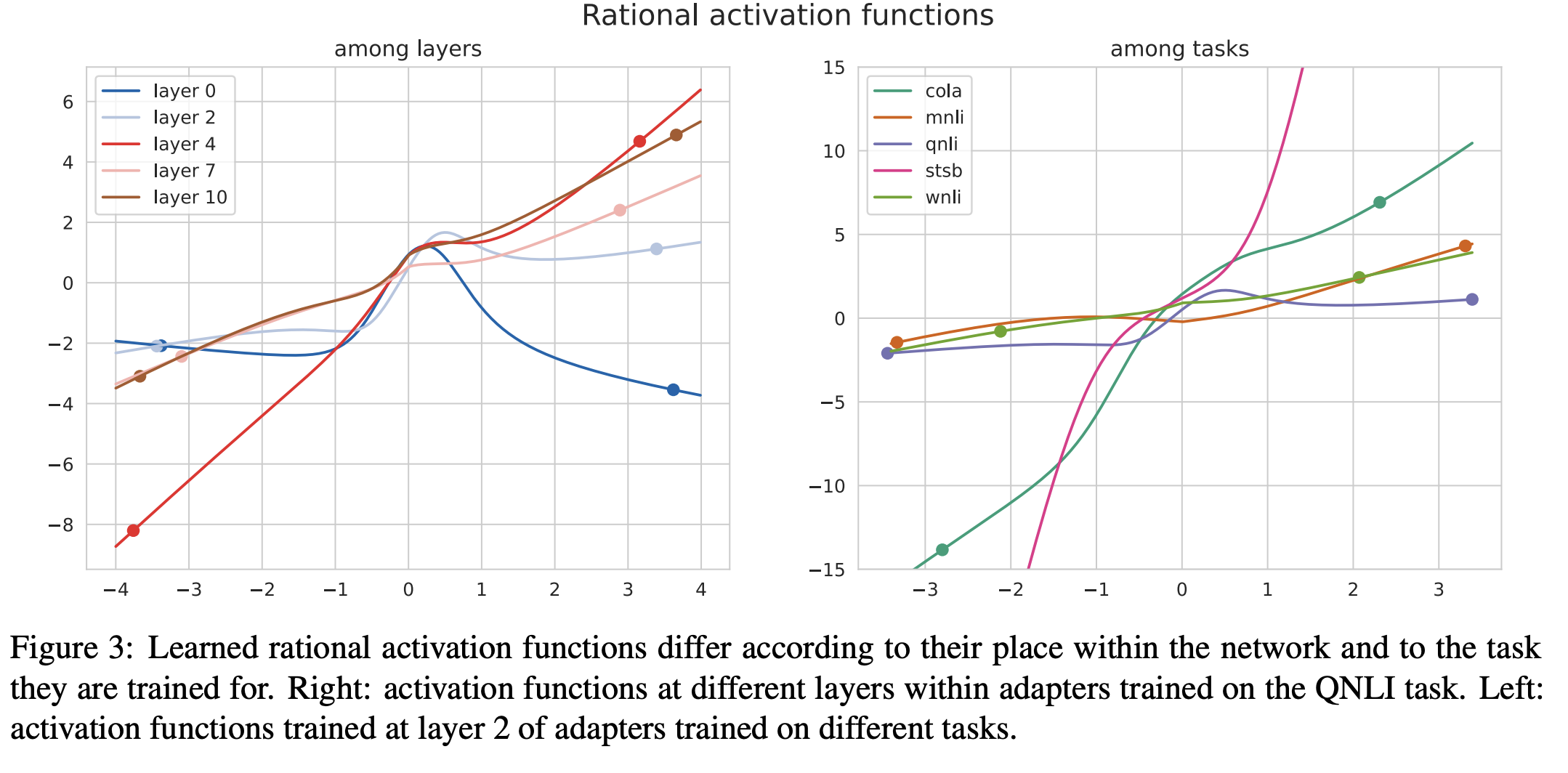
AA learned rational optimization functions
Reference
@inproceedings{Moosavi2022AdaptableA,
title={Adaptable Adapters},
author={Nafise Sadat Moosavi and Quentin Delfosse and Kristian Kersting and Iryna Gurevych},
year={2022}
}