
Condenser
Introduction
-
What is the name of the condenser paper?
Condenser: a Pre-training Architecture for Dense Retrieval
Luyu Gao and Jamie Callan, LTI, CMU
- What are the main contributions of the condenser paper?
- novel pretraining objective to optimize transformers for biencoding
- optimized more easily on dense representation tasks
- One problem with BERT NSP training of CLS token is that
it only receives attention from other tokens in the final layer- for good dense representation information should start being aggregated at earlier layers
Method
- Condenser was inspired by
funnel transformerandunet -
Condenser pretraining is done with skip connections from
early output to condensor head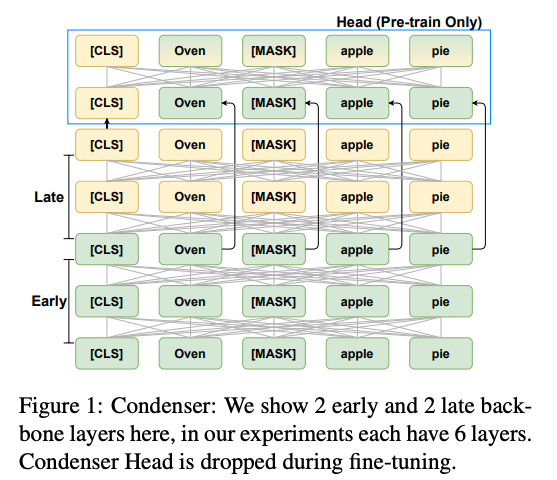
- Condensor Head perform masked language modeling using
late CLS representation and early layer contextual mask and token representations - The intuition behind condenser is to force the model to
encode more structural information from all layers in CLS representation - Condenser finetuning is done
normally- condenser head is droped
Results
-
Condenser STS results
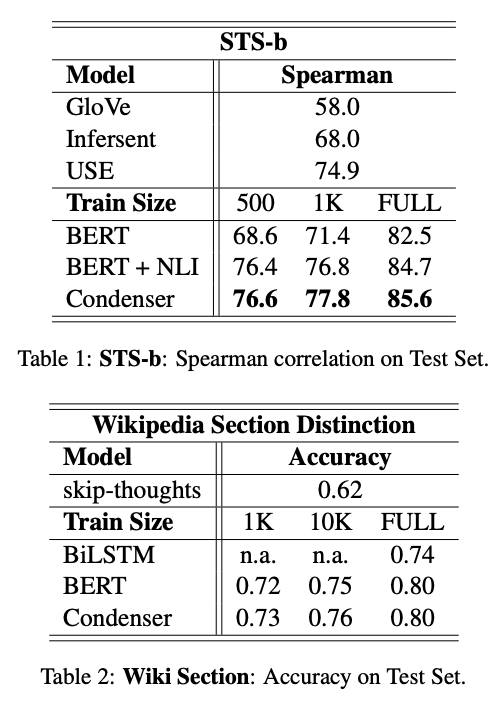
-
Condenser: MSMARCO results outperforms
two decent baselines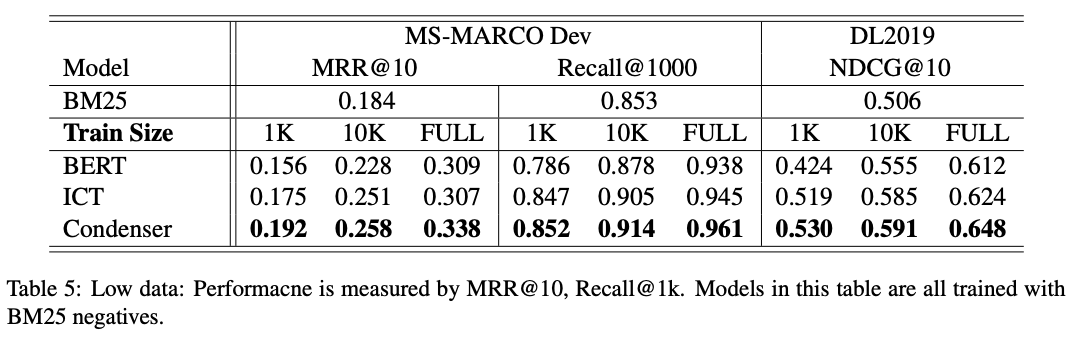
Conclusions
Would like to see stronger baselines like SIMCSE etc. It makes sense in principle but has to be worth the cost of full pretraining. Also for clarity they should probably refer to SBERT as SBERT instead of BERT since it only requires one more character. I wonder whether this pretraining would benefit roBERTa more because theoretically roBERTa might have a less expressive [CLS] token representation due to the lack of the NSP pretraining task.
Reference
@misc{https://doi.org/10.48550/arxiv.2104.08253,
doi = {10.48550/ARXIV.2104.08253},
url = {https://arxiv.org/abs/2104.08253},
author = {Gao, Luyu and Callan, Jamie},
keywords = {Computation and Language (cs.CL), Information Retrieval (cs.IR), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Condenser: a Pre-training Architecture for Dense Retrieval},
publisher = {arXiv},
year = {2021},
copyright = {arXiv.org perpetual, non-exclusive license}
}