
GrIPS: Gradient-free, Edit-based Instruction Search for Prompting Large Language Models
Introduction
-
What is the name of the GrIPS paper?
**GrIPS: Gradient-free, Edit-based Instruction Search for Prompting Large Language Models**
Archiki Prasad Peter Hase Xiang Zhou Mohit Bansal, UNC Chapel Hill
- What are the main contributions of the GrIPS paper?
- Gradient Free method to improve performance of GPT models on natural instructions
- Improved Performance for instruct GPT and manual rewriting
- Can improve instructions with as few as 20 data points
- Show that models can benefit from semantically incoherent instructions
- One of the main motivations for gradient free optimization of prompts for generative models is
models are behind openai paywall
Method
- GrIPS paper follows the prompt format from the
Natural instruction paper- Format is
InstructionsorInstructions + Examples - note: I contributed to the Natural Instructions v2 paper
- Format is
- GrIPS optimizes instructional prompt by editing instructions and
greedily selecting best edit- search guided by performance on a small score set (100 examples)
- generate mxl new candidates at each step

- GrIPS scores is a combination of balanced accuracy and
entropy of class predictions- entropy term is to encourage diverse label output
-
GrIPS instructions are broken into phrases using a
SOTA CRF based constituency parser - GrIPS generates new prompting candidates by applying 4 primary edit operations
- delete
- swap
- paraphrase (use pegasus model)
- addition: add back in a previously deleted phrase
This reminds me of the operations performs in the Monte Carlo search in Bayesian Rule Lists
Results
-
GrIPS on average gives
several points of performanceincrease over GPT models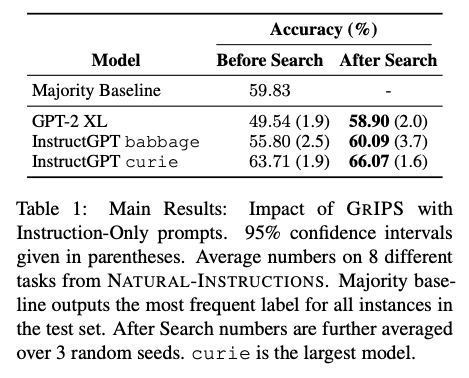
-
GrIPS generates better performing instructions even if they are
semantically incoherent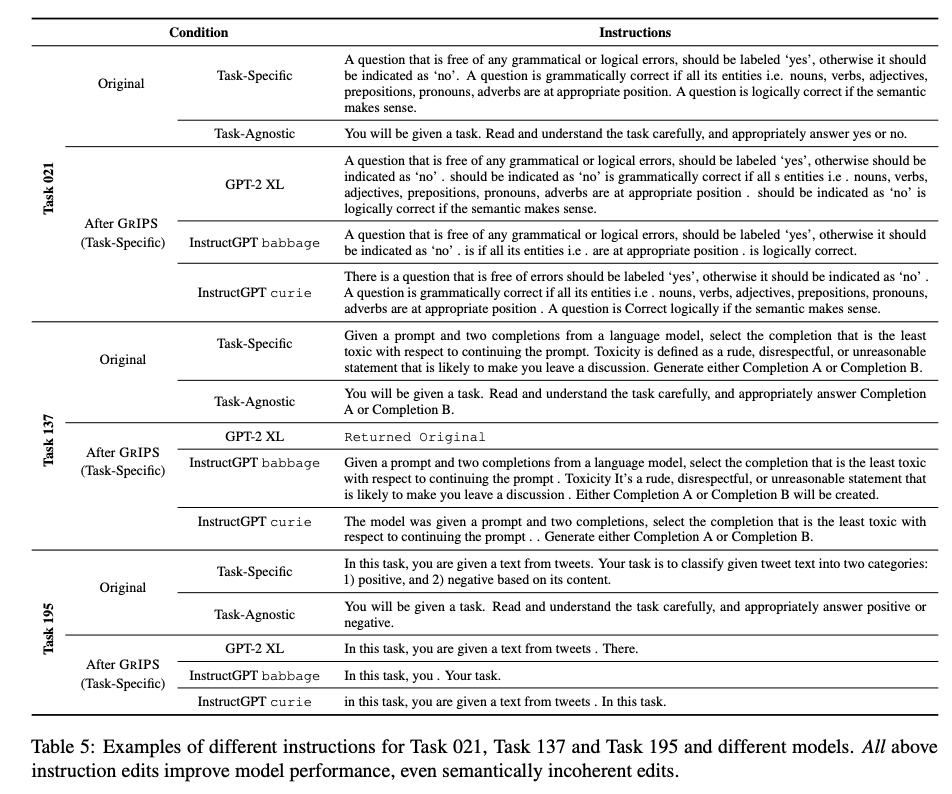
Conclusions
Obviously would be interesting to compare to actual finetuning on a similarly sized training set (ie finetune on a number of examples equal to the size of the scoring set. However this paper shows a promising gradient free approach to optimizing generative models.
Reference
@article{Prasad2022GrIPS,
title = {GrIPS: Gradient-free, Edit-based Instruction Search for Prompting Large Language Models},
author = {Archiki Prasad and Peter Hase and Xiang Zhou and Mohit Bansal},
year = {2022},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
eprint = {2203.07281}
}