
Deep Continuous Prompt for Contrastive Learning of Sentence Embeddings
Introduction
-
What is the name of the DCPCSE paper?
Deep Continuous Prompt for Contrastive Learning of Sentence Embeddings
Current ACL submission
-
What are the main contributions of the DCPCSE paper?
- contrastive training of sentence embeddings
- use continuous prompts
- keep pretrained language model parameters frozen
- outperform SIMSCE on many STS tasks
Method
- DCPSE freezes the transformer parameters and only trains the
prefix continuous prompts- very parameter efficient
- very similar to the prefix tuning approach: prompts are applied at each layer
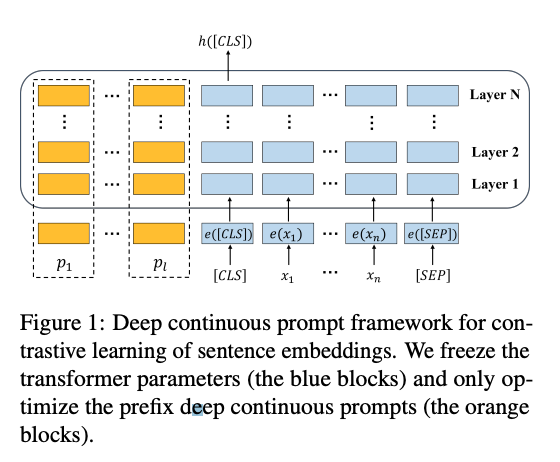
- DCPCSE uses a standard contrastive pretraining objective combined with an
auxiliary MLM task- positive pairs are generated using inner dropout the same as in SIMCSE
- 15% of tokens are randomly masked out
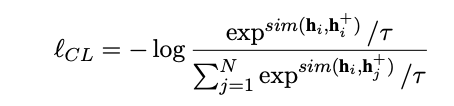
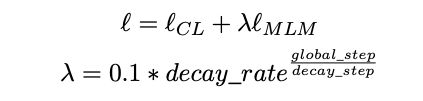
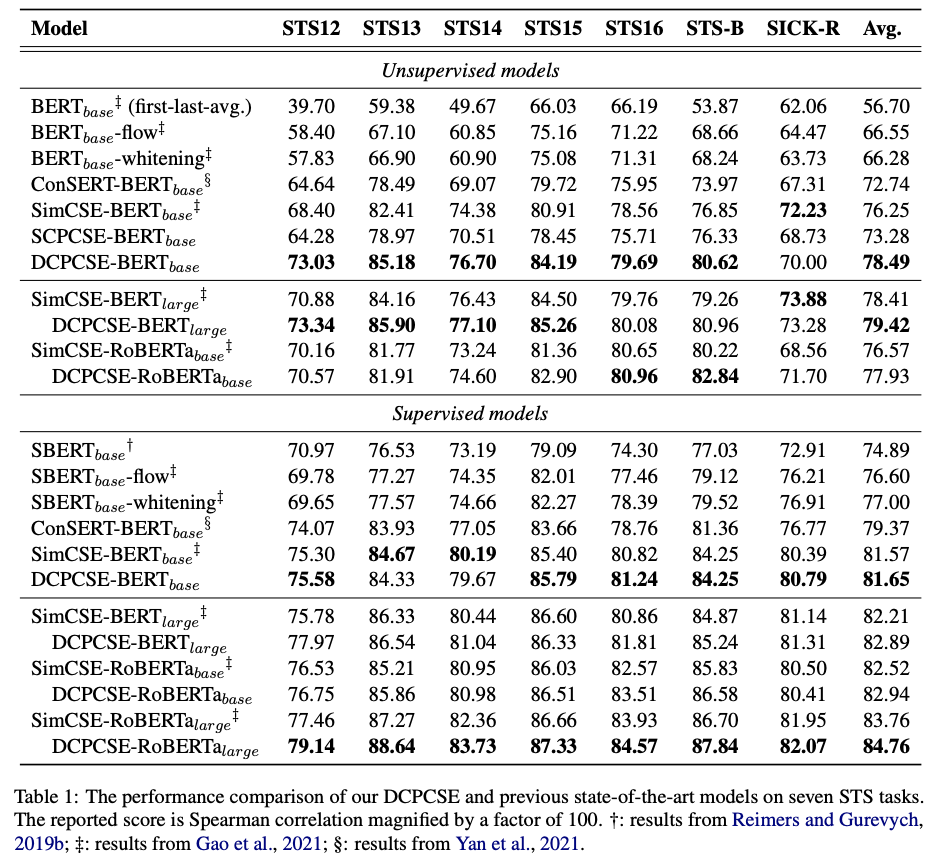
Results
- DCPCSE achieves strong results on
STStasks- no senteval results
- note concurrent work
gets very competitive results when comparing roBERTa- base models
-
DCPCSE performance scales
stronglywith prompt length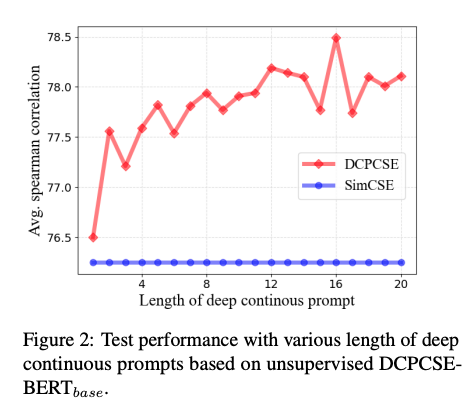
- DCPCSE variant SCPCSE trains only the
input embeddings initialize from a soft prompt template- template is This sentence : “[X]” means [MASK]
- This approach is much more comparable to promptBERT
Conclusions
Overall this is a good paper in an area I am interested in but with somewhat confusing writing and presentation. I am really impressed at the state-of-the-art results achieved with only 0.1% trainable parameters. However there is a lot of confusing writing/ omissions in this short paper. For one part the authors should explicitly mention that they generate positive samples using inner dropout equivalent to SIMCSE in the paper rather than leaving it to the appendix. Likewise, they should recognize that using an auxiliary MLM loss when training continuous prompts was inspired by multiple previous works (DART and AUTOPROMPT) instead of something that they took away from the BERT paper. In those works, the MLM loss was explained more as a “fluency constraint objective”. The DCPCSE author’s explanation of MLM loss as helping avoid local minima is not well motivated. The SCPCSE ablation experiment is a little strange and pretty much exactly replicates the prompt best method. A more interesting ablation would be to see whether only tuning the inputs to the first layer would affect results. In addition, I think the authors should motivate why parameter efficiency is important in this setting. If we want to train a model for better sentence representation we might as well train all parameters if this will give us better performance. In fact, this would make an interesting ablation experiment: if they do not freeze the main language model parameters could performance be improved even further?
The results of the paper are very nice, achieving SOTA on STS tasks. However concurrent work promptBERT achieves basically the same results (albeit while training a larger number of parameters). I’d want to see senteval results for DCPCSE in order to fully compare these sentence embedding methods since STS results alone might not reveal enough about downstream performance. In the spirit of reviewing I would give this paper a weak accept. A lot of the motivations and explanations could be improved and some more focused experiments could be performed.
Reference
https://openreview.net/pdf?id=JlzYVoUnCQo