
Cluster & Tune: Boost Cold Start Performance in Text Classification
Introduction
-
What is the name of the Cluster and Tune paper?
Cluster & Tune: Boost Cold Start Performance in Text Classification
-
What are the main contributions of the Cluster and Tune paper?
- efficient clustering technique based on BOW representations
- train on text classification objective on clusters
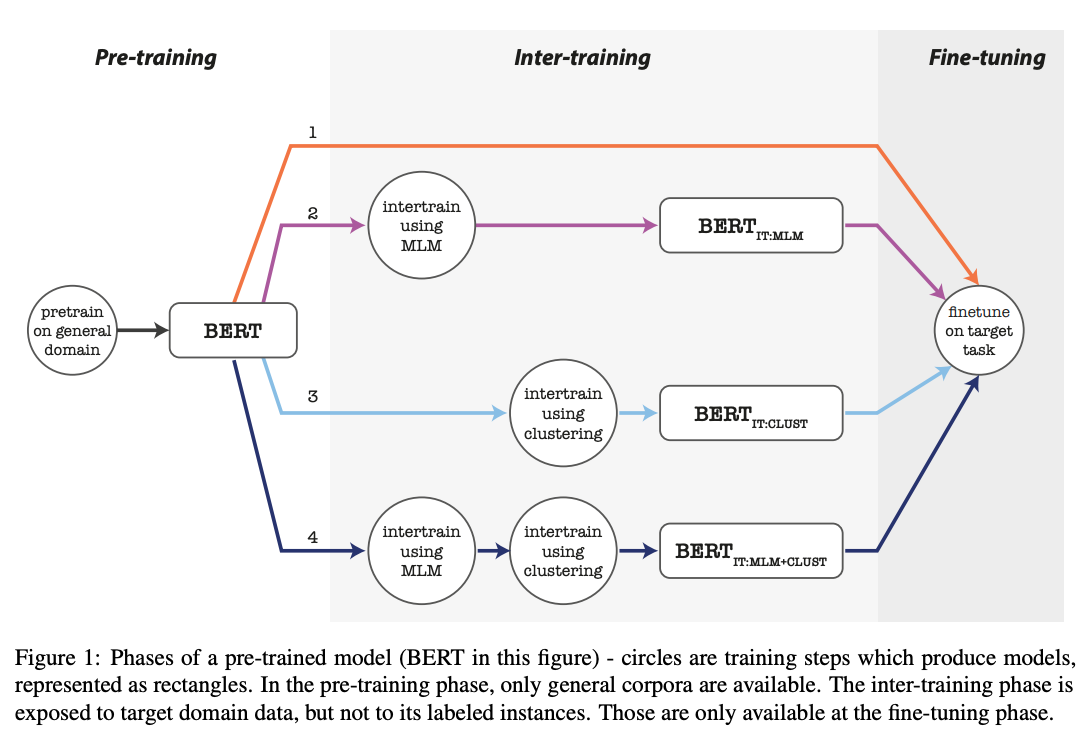
Method
- The main intuition behind cluster and tune is that a
text classification intertuning objective is more relevant to the downstream tasks- MLM ICT method might overfit to a different objective
- Note: for Verbalizer style classifiers that make use of MLM, MLM ICT might be better
- Clustering code start presents an extension to
In domain continued pretraining- often in domain continued pretraining can give a small boost
- now we also train on a cluster classification objective
Results
- Cluster and Tune has better performance on datasets that are
more topical- domain adaptation more important
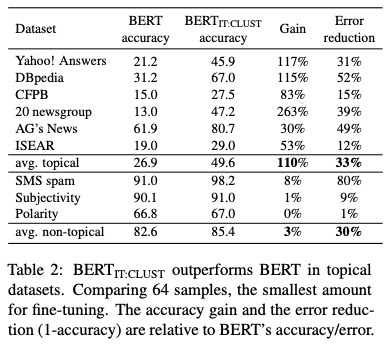
- Cluster and Tune clustered sentence embeddings tend to cluster
along class lines- no labels shown to the model
- note: How much does this depend on the inherit ability of classes in a task to be clustered in a simple BOW representation

-
Cluster and Tune experience biggest boost in performance in the
few shot domain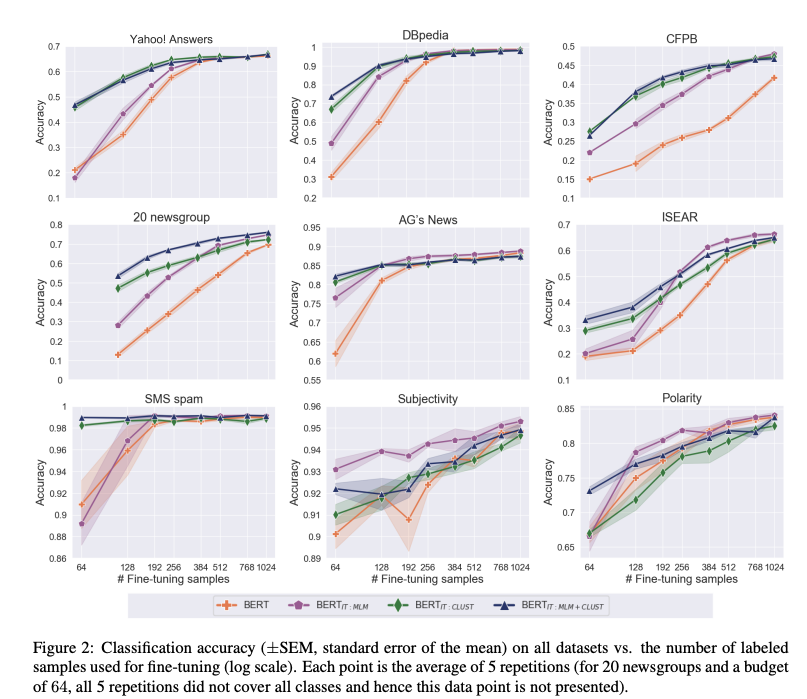
Conclusions
Domain adaptation with unlabeled in-domain data is particularly important for practical Machine Learning use cases. This method presents a simple method to leverage this unlabeled data to improve in domain performance. Cluster and Tune is probably equivalent to other pseudo labeling methods that basically perform entropy regularization. I’d like to see a direct comparison to pseudo labeling the unlabeled data based on few shot finetuned model and then retraining. It’s nice to have a toolkit of methods to boot text classification performance on a specific dataset. This paper is a good addition to the simple In domain Continued Training method.
Reference
@misc{https://doi.org/10.48550/arxiv.2203.10581,
doi = {10.48550/ARXIV.2203.10581},
url = {https://arxiv.org/abs/2203.10581},
author = {Shnarch, Eyal and Gera, Ariel and Halfon, Alon and Dankin, Lena and Choshen, Leshem and Aharonov, Ranit and Slonim, Noam},
keywords = {Computation and Language (cs.CL), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Cluster & Tune: Boost Cold Start Performance in Text Classification},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Non Commercial No Derivatives 4.0 International}
}