
AdaPrompt: Adaptive Model Training for Prompt-based NLP
Introduction
-
What is the name of the AdaPrompt paper?
AdaPrompt: Adaptive Model Training for Prompt-based NLP
-
What are the main contribution of the AdaPrompt paper?
- use external knowledge to expand vocab set for prompt verbalizers
- outperform baselines in few shot or zero shot domain
Method
-
Adaprompt method queries an
external databaseto help choose better verbalizers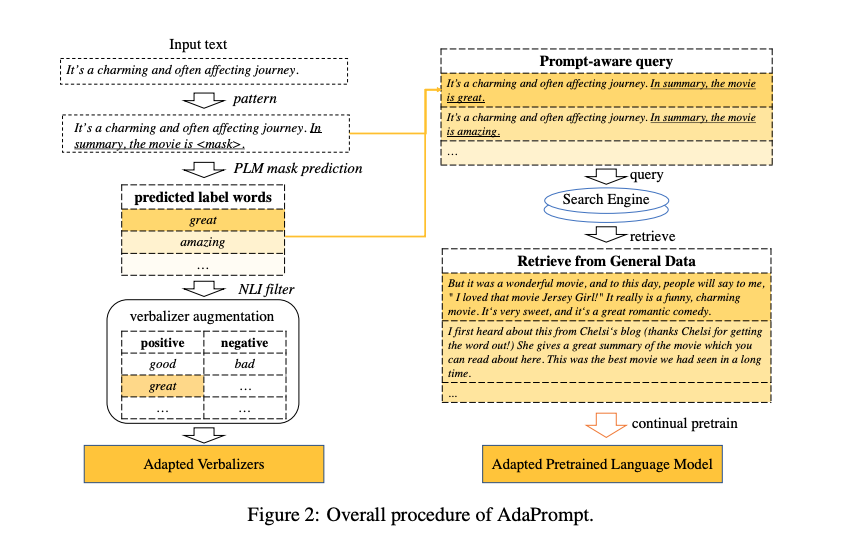
- Adaprompt uses queries to retrieve in domain data for a specific task from a
large data source- they use elastisearch with tfidf vectors
- use the retrieved sentences for an ICP step with MLM loss
-
Adapromopt gets new verbalizer candidates using a NLI model to score
top k candidate words for [MASK] token in verbalizer prompt
Results
-
Adaprompt gives good boost in the
few shot regime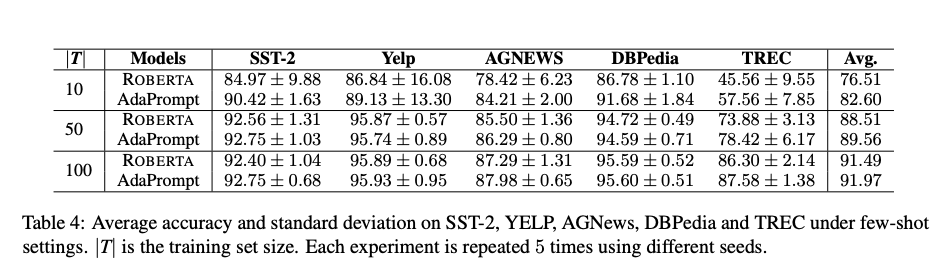
Conclusions
Adaprompt is primarily a combination of two discrete and relatively unrelated methods. First, a retrieval method is used to prioritize in-domain data for an In domain Continued Pretraining step. Second, a method is used to augment the verbalizer space. I find the first method more interesting and their results approximately match what is expected from the ICP paper. More advanced retrieval methods based on SBERT style embeddings instead of tfidf could potentially improve results. However, of course, the added cost of in-domain pretraining mitigates the benefits of learning in the few-shot regime. The second method of searching for discrete prompts is interesting but probably not going to beat differentially training a soft verbalizer such as in methods like DART. In addition, it has the disadvantage of requiring an external NLI model.
Reference
@article{chen2022adaprompt,
title={AdaPrompt: Adaptive Model Training for Prompt-based NLP},
author={Chen, Yulong and Liu, Yang and Dong, Li and Wang, Shuohang and Zhu, Chenguang and Zeng, Michael and Zhang, Yue},
journal={arXiv preprint arXiv:2202.04824},
year={2022}
}