
elBERto: Self-supervised Commonsense Learning for Question Answering
Introduction
-
What is the name of the elBERTo paper?
elBERto: Self-supervised Commonsense Learning for Question Answering
-
elBERTo stands for
Selfsupervised Bidirectional Encoder Representation Learning of Commonsense - What are the main contributions of the elBERTo paper?
- 5 self supervised tasks to encourage models to perform commonsense reasoning with context
- novel Contrastive Relation Learning (CRL) task to help QA solvers to
- Jigsaw Puzzle (JP) task
- SOTA performance on commonsense QA tasks
- What are the claimed advantages of the elBERTo model?
- in domain training corpus
- no extra training time
- improved commonsense question answering
- Approaches to commonsense QA fall into two main categories
- Retrieving evidence paths from external knowledge base
- Knowledge Graph propagation based approaches
Method
-
Context in commonsense multiple choice question answering can consist of
complex relations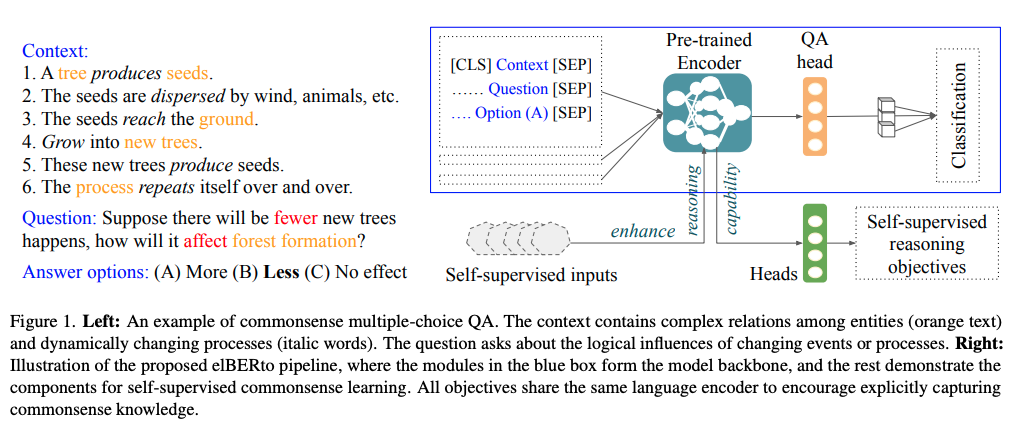
- How are commonsense multiple choice question answering tasks formulated?
- context
- question
- answer choices
- Want to optimize likelihood of ground truth answer under model
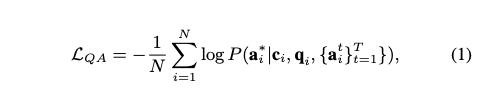
-
elBERTo paper proposes a large number of SSL tasks

- elBERTo Contrastive Relation Learning tasks asks a model to distinguish between original and
flippedcontexts- flip words in context to antonyms
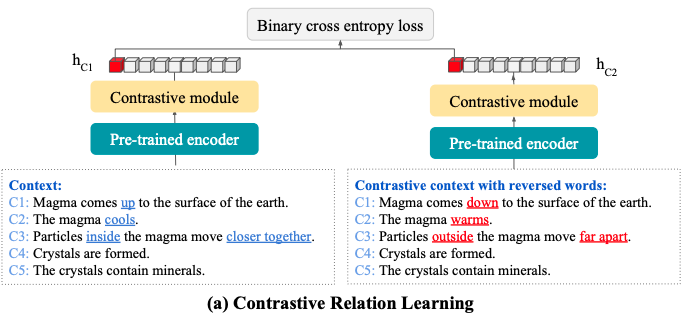
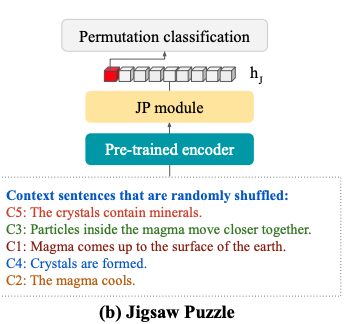
- The elBERTo jigsaw puzzle task aims to predict the
correct order out of k ordered sequential contexts- aims is to prompt model to learn sequential relationships
-
elBERTo motivation for using Binary Sentence Order Prediction is that
contexts for commonsense question answering exhibit causal relationships between consecutive sentences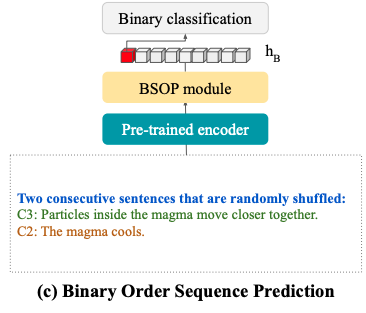
- elBERTo uses Tagme to extract entities for
masked entity modeling
Results
- What are some examples of commonsense QA datasets?
- WIQA: What if questions
- CosmosQA: human daily life scenarios
- ReClor: from graduate admission exams
-
elBERTo results: adding pretraining tasks leads to
improvement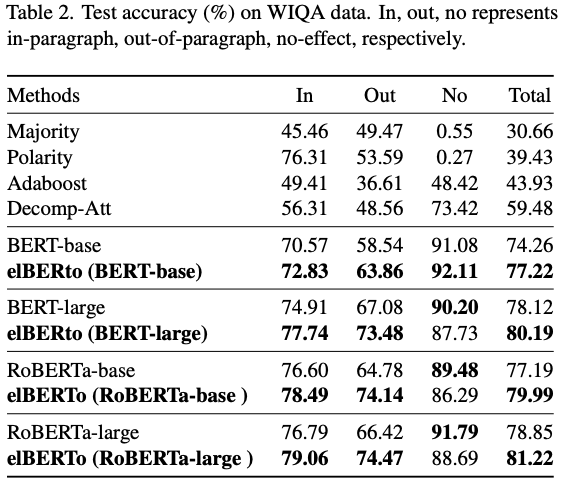
-
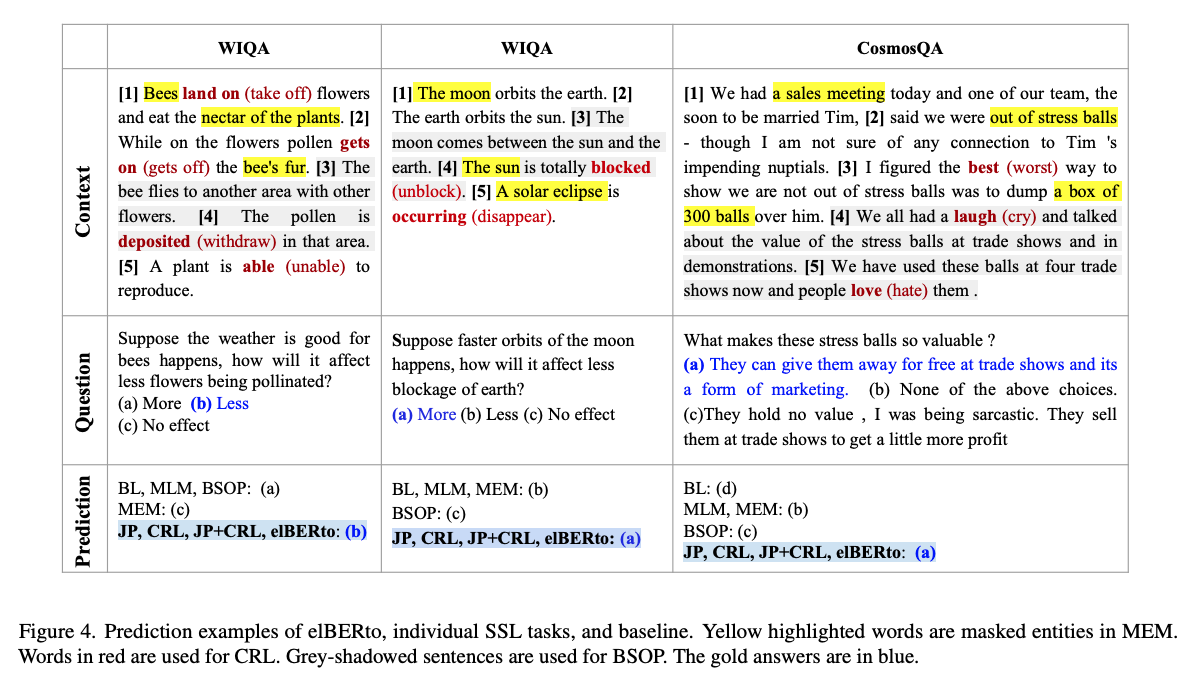
elBERTo predictions examples:
Conclusions
This paper presents a number of pretraining tasks that improve performance on Commonsense QA tasks. These question answering tasks are very interesting because they require more compositional reasoning compared to other NLP tasks and are less susceptible to shortcut learning. Overall this is a good paper and the pretraining tasks seem well motivated. I think in general it’s a good domain of research to explore how pretraining tasks can be used to encode specific inductive biases into smaller models like the BERT models used in this dataset. I feel this approach will be complementary to the multitask pretraining and finetuning going into larger models like t0 and FLAN. For practical use cases it will often be better to use that smaller model with a specialized pretraining task rather than a larger model even thought the larger model might have good zero shot or few shot performance.
Reference
@article{zhan2022elberto,
title={elBERto: Self-supervised Commonsense Learning for Question Answering},
author={Zhan, Xunlin and Li, Yuan and Dong, Xiao and Liang, Xiaodan and Hu, Zhiting and Carin, Lawrence},
journal={arXiv preprint arXiv:2203.09424},
year={2022}
}