
Trial2Vec
Trial2Vec
-
What is the name of the Trial2Vec paper?
Trial2Vec: Zero-Shot Clinical Trial Document Similarity Search using Self Supervision
- What are the main contributions of the Trial2Vec paper?
- CL method to get embeddings taking into account trial meta-structure
- improvement over baselines on trial retrieval task
- Why is clinical trial retrieval important?
- When constructing clinical trial it is important to study similar trials
- What are the main challenges stated by Trial2vec for clinical trial retrieval?
- long documents beyond BERT context window
- inefficient contrastive supervision
- traditional approaches rely on entity matching
Method
-
Trial2Vec backbone model is BioBERT with continued MLM pretraining on
clinical trial texts -
TrialBERT contrastive training uses
global and local contrastive loss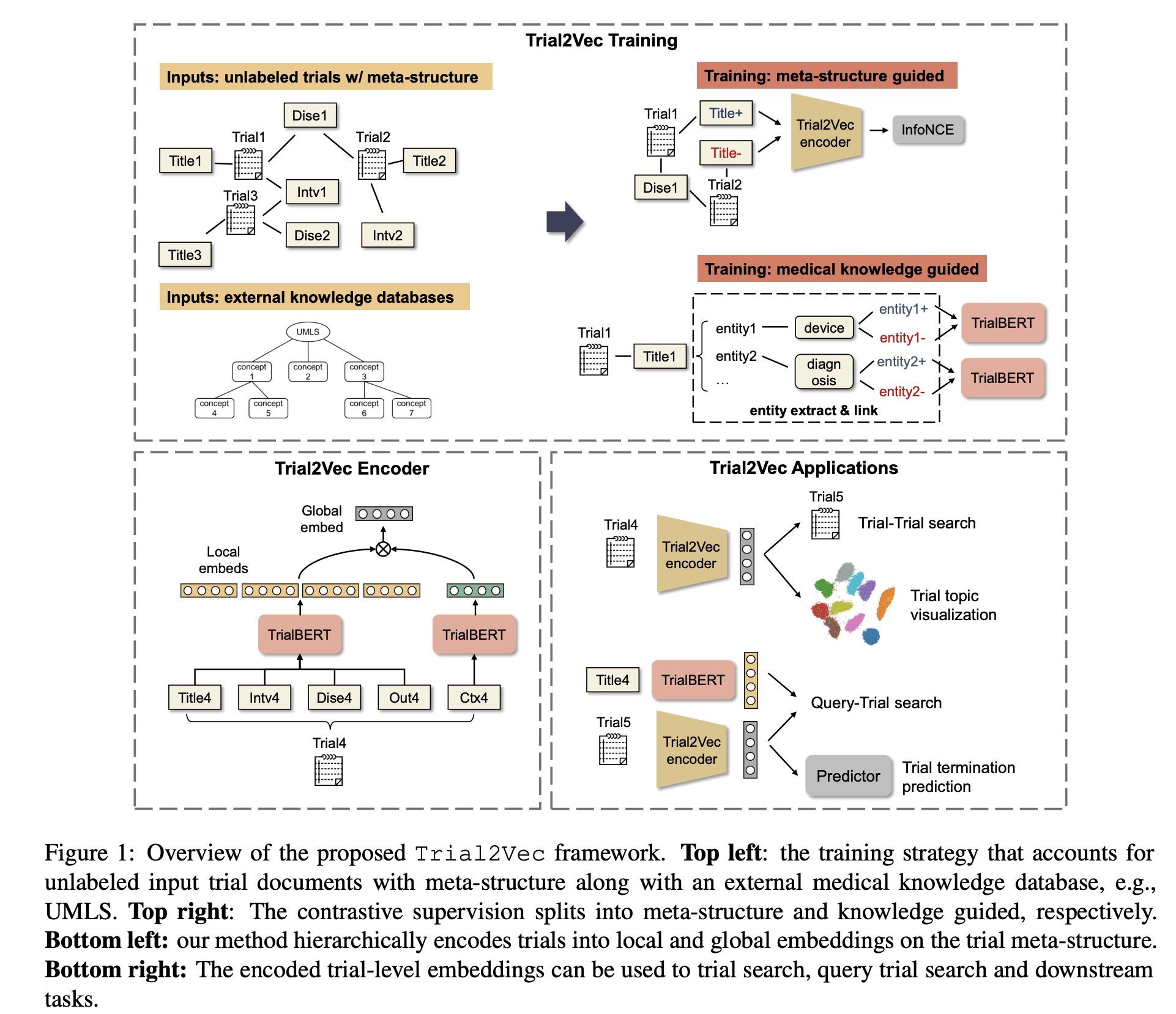
- TrialBERT global contastive loss is on
positive sample with random attribute dropoutand hard negative byswapping out one attribute- embeds are pooled separately across attribues
- TrialBERT local contrastive loss generates negative samples by
deleting or swapping key medical entities- positive samples are generated by replacing entity with canonical name or similar entity defined under UMLS (external knowledge)
Results
-
Trial2Vec good performance on
clinical trial retrieval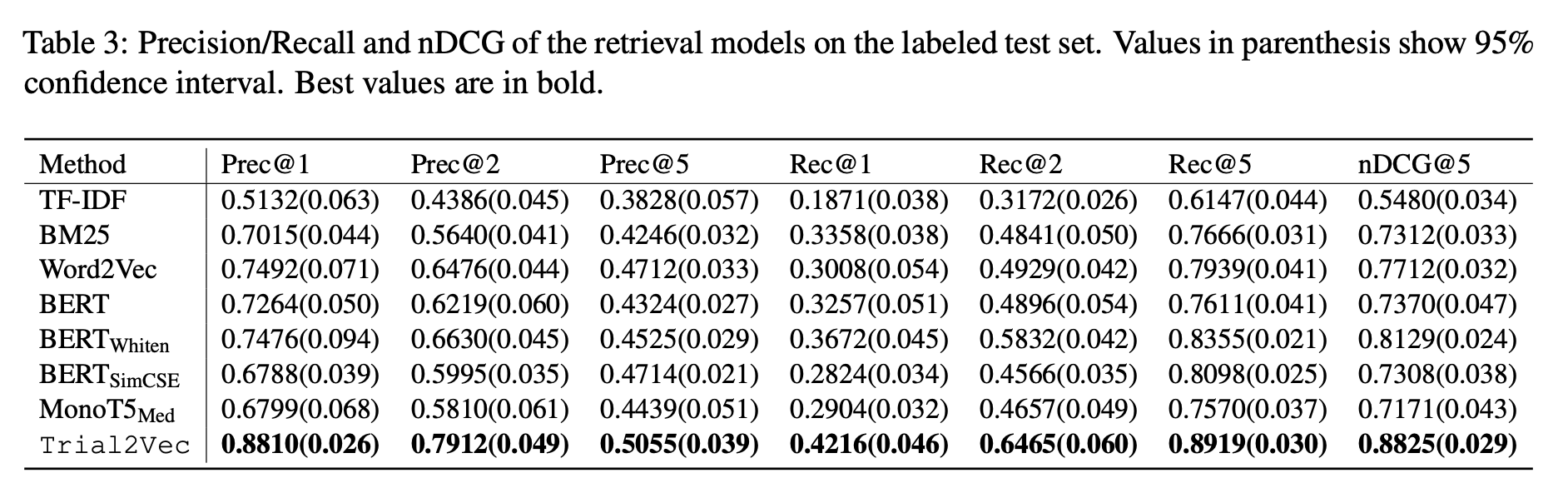
-
Trial2vec clustering: clusters well by
disease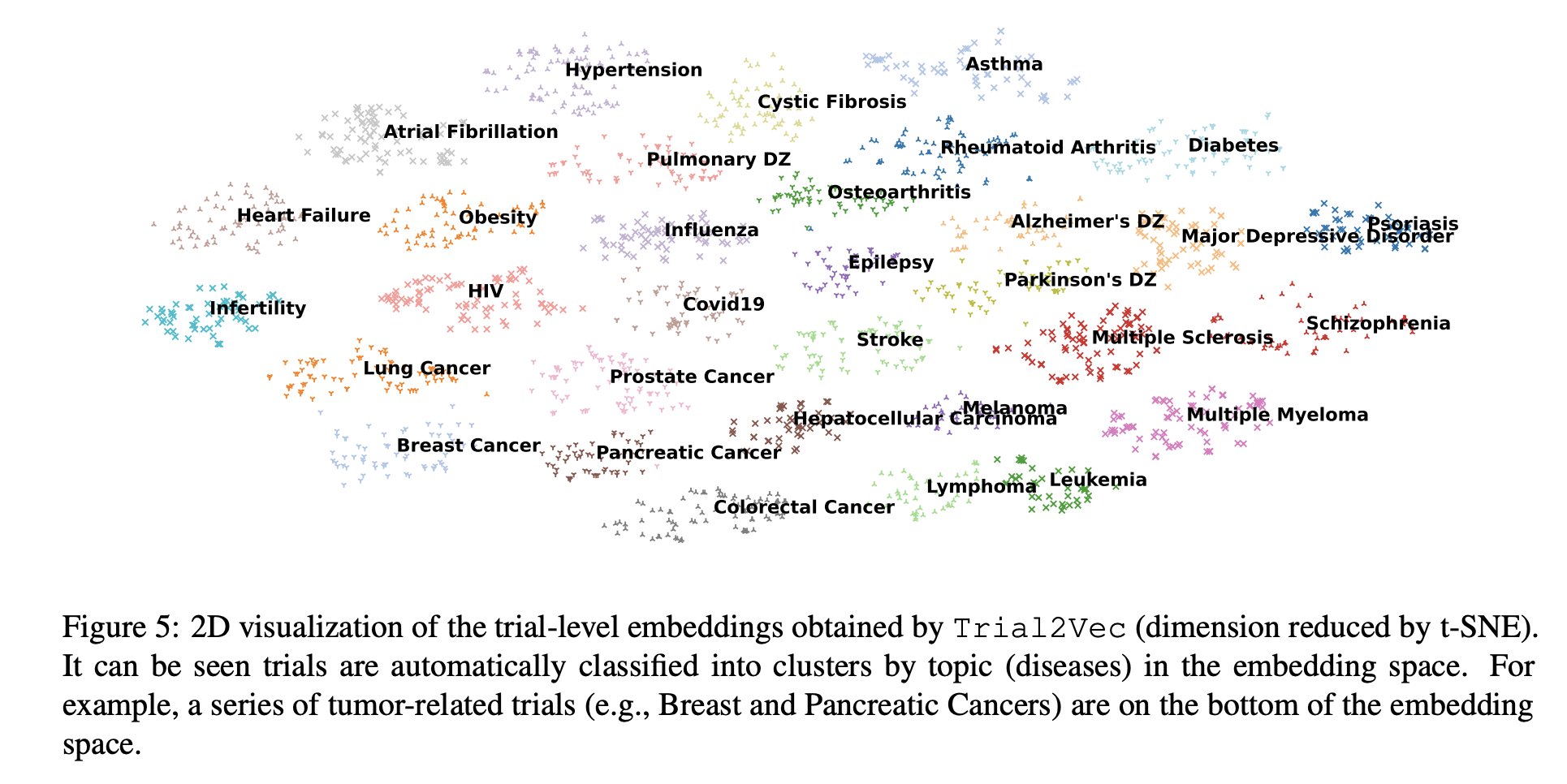
-
Trial2Vec clinical outcome prediction: only
1% better than tfidf features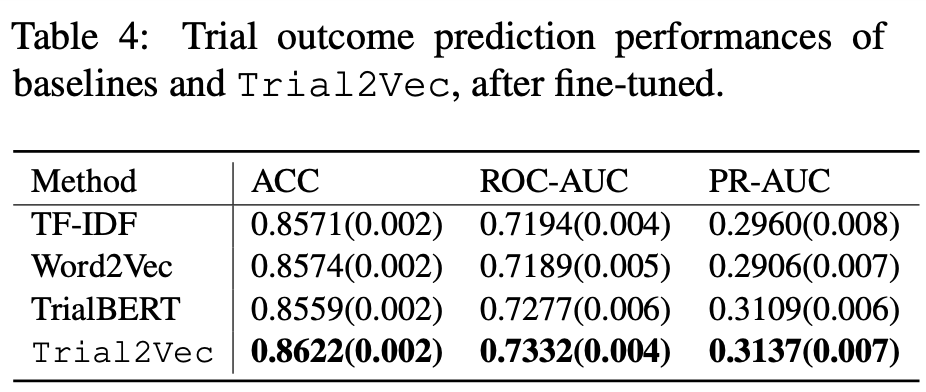
-
Key takeaways from Trial2Vec method
It’s possible to construct better retrieval methods very tailored to your domain
Trial2Vec leverages several key approaches
- ICP on relevant data
- Taking advantage of key metastructure to encode long documents
- Take advantage of an external knowledge base (UMLS)
- Carefully construct global and local contrastive training objectives
Conclusion
It’s nice to see that a well constructed contrastive learning task can lead to great information retrieval performance in a very specific domain.
Reference
@misc{https://doi.org/10.48550/arxiv.2206.14719,
doi = {10.48550/ARXIV.2206.14719},
url = {https://arxiv.org/abs/2206.14719},
author = {Wang, Zifeng and Sun, Jimeng},
keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Trial2Vec: Zero-Shot Clinical Trial Document Similarity Search using Self-Supervision},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}