
STRUCTURE AND SEMANTICS PRESERVING DOCUMENT Representations
Introduction
-
What is the name of the document Structure paper?
STRUCTURE AND SEMANTICS PRESERVING DOCUMENT REPRESENTATIONS
Natraj Raman, Sameena Shah and Manuela Veloso2
- What are the main contributions of the Document Structure paper?
- methods to take advantage of inter document relationships
- Structure Mining: method to get similar and dissimilar pairs of documents
- Relative Margins: discriminative treatment of the representation space
- Inductive and Finetunable method
- quintuplet loss formulation
- Inherent challenges in document retrieval
- long form text
- corpus size
- query-document vocabulary mismatch
- asymmetry in length between query and document
Method
- Document structure paper assumes
adjacency matrix of document relations is known- use page rank to get connection strengths based on entire graph
- rank documents by connectedness to an anchor
- bucket into different levels of relatedness
-
Structural pair construction from document graph: positive sample sampled uniformly from
top l documents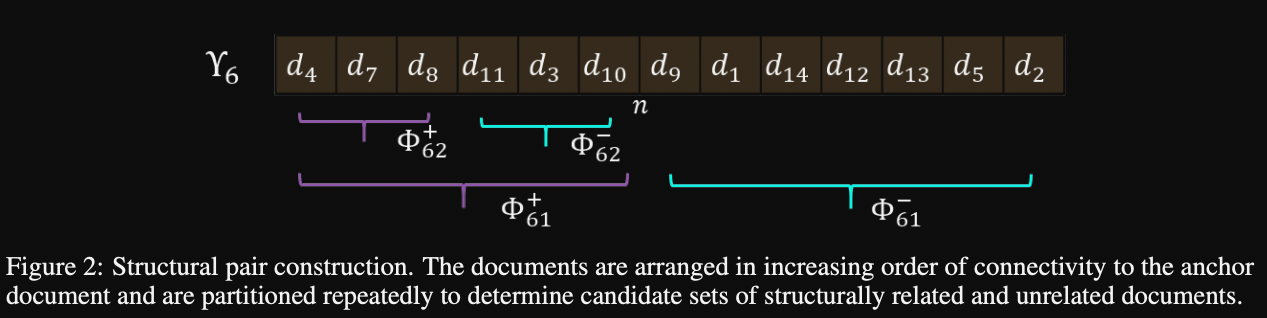
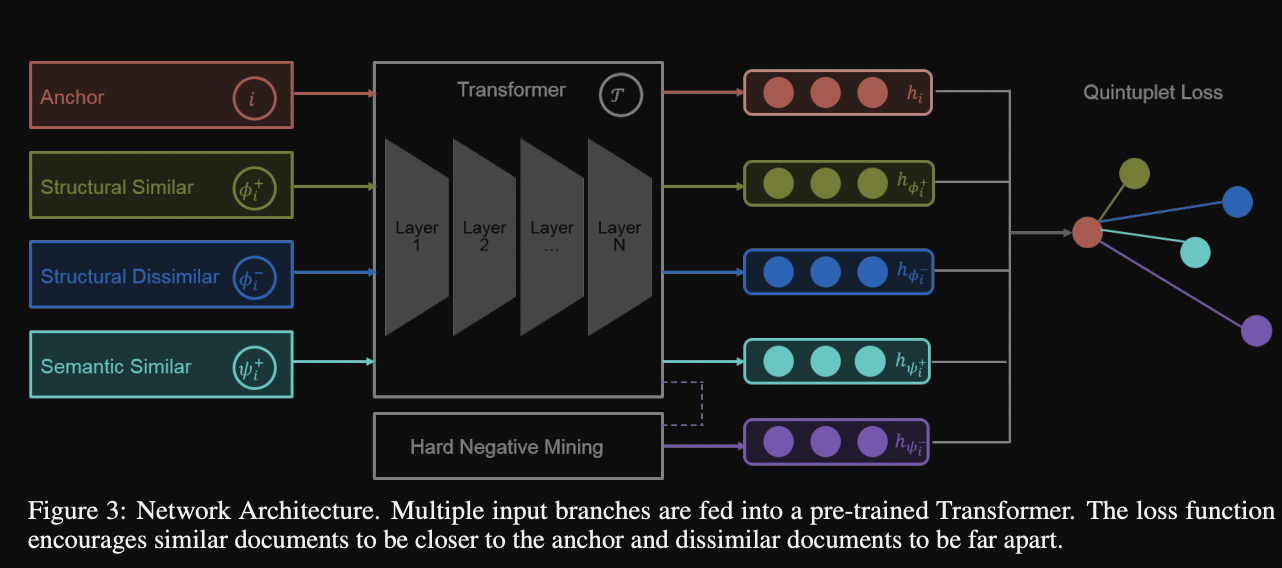
- Quintuplet loss for information retrieval makes use of
5 different inputs- $h_i$: anchor
- $h_{\phi_i^+}$: structural similar
- $h_{\phi_i^-}$: structural dissimilar
- $h_{\psi_i^+}$: semantic similar: from token or mask replacement
- $h_{\psi_i^-}$: hard negative
- Document structure semantically relevant document is sampled by
corrupting the anchor by replacing 25% of tokens- treated as a positive sample
- Document structure quintuplet loss requires
4 forward passes through model- total of 5 embeddings → each loss term
- Document structure samples a
random chunkfrom each document to feed to transformer- still trains smaller chunks
-
Document structure: document score is
aggregate of score for each chunk - Document structure evaluation dataset is Scidocs
abstracts and citation graph
Results
-
Document Structure results: outperform
sciBERT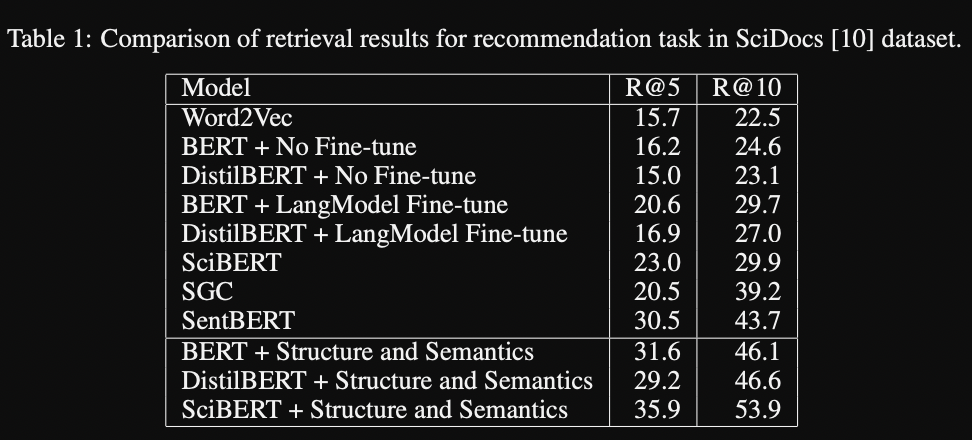
-
Embeddings distance based on relationship strength
(citation graph hop count)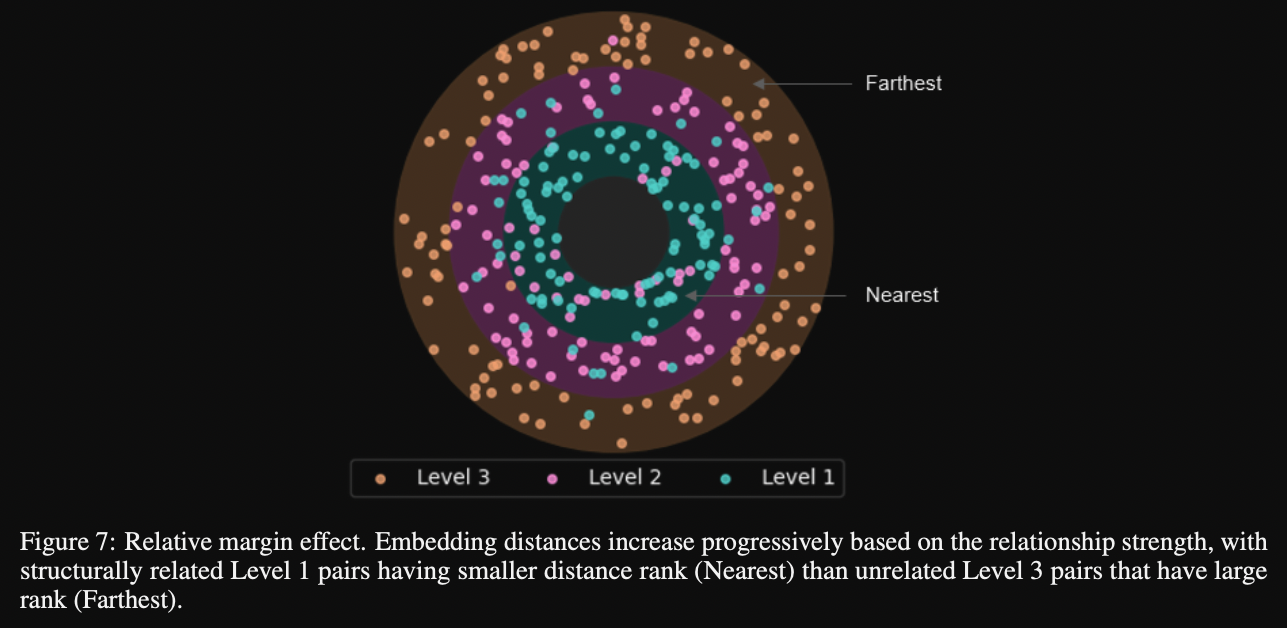
Conclusions
Extensions to this paper could include:
- leveraging document relation structure in other domains
- mean pooling text fragments to get a single document representation
- using some sort of weighed infoNCE loss for more efficient training
Reference
@article{DBLP:journals/corr/abs-2201-03720,
author = {Natraj Raman and
Sameena Shah and
Manuela Veloso},
title = {Structure with Semantics: Exploiting Document Relations for Retrieval},
journal = {CoRR},
volume = {abs/2201.03720},
year = {2022},
url = {https://arxiv.org/abs/2201.03720},
eprinttype = {arXiv},
eprint = {2201.03720},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03720.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}