
Multi-View Document Representation Learning for Open-Domain
Type: Paper
Introduction
-
What is the name of the multiview document encoding paper?
Multi-View Document Representation Learning for Open-Domain Dense Retrieval
-
What are the main contributions of the multiview document encoding paper?
Method
-
MVR paper generates multiple embeddings of a document from
special view token hidden representations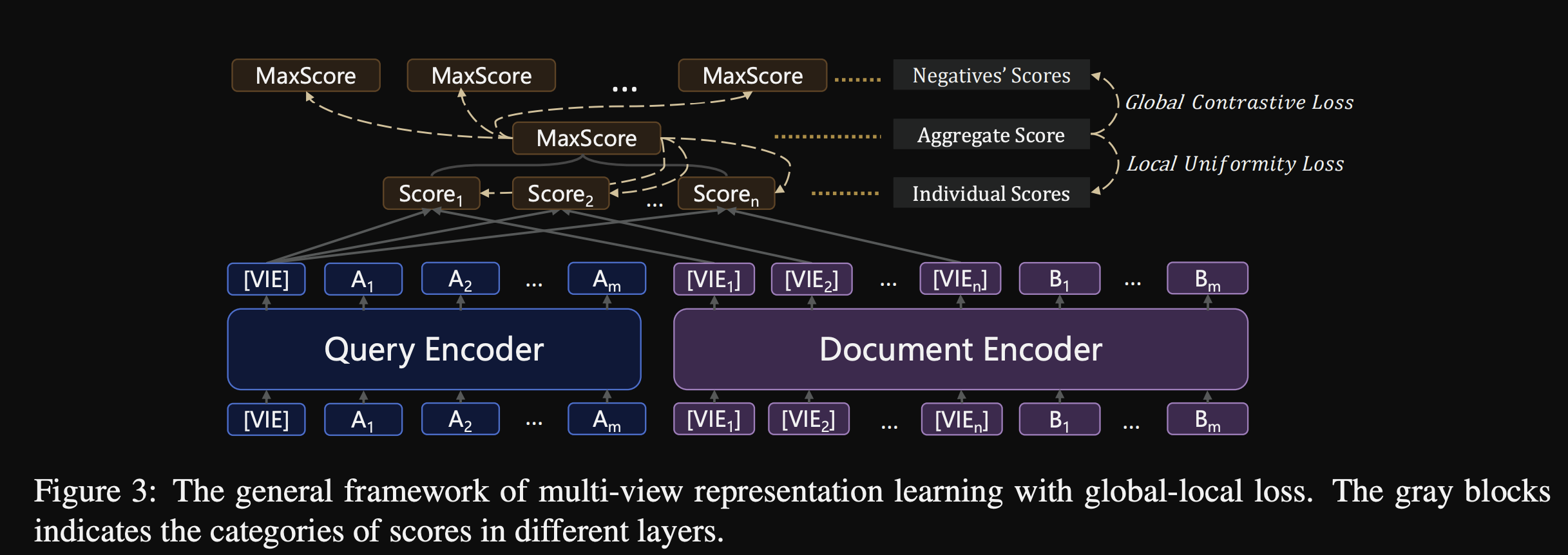
-
MVR the score between a query and a document is a
max over similarity with each view representation -
MVR view representations are trained using
global local loss - The global loss in MVR encourages the
query and document representations to align- normal contrastive loss
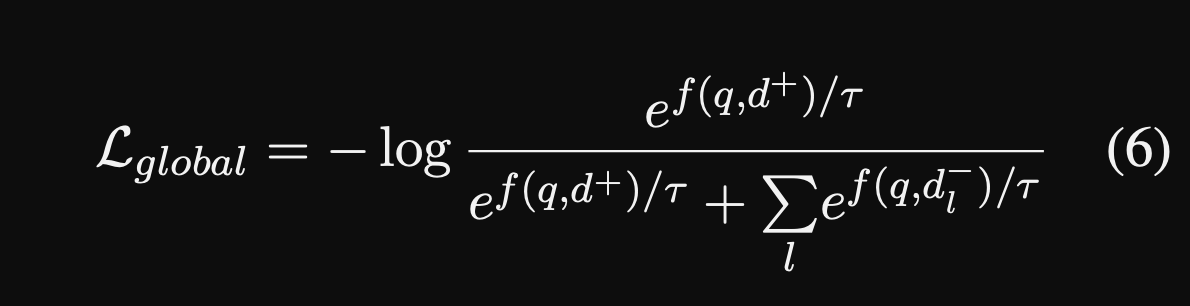
-
The local loss in MVR encourages the
document view representations to spread out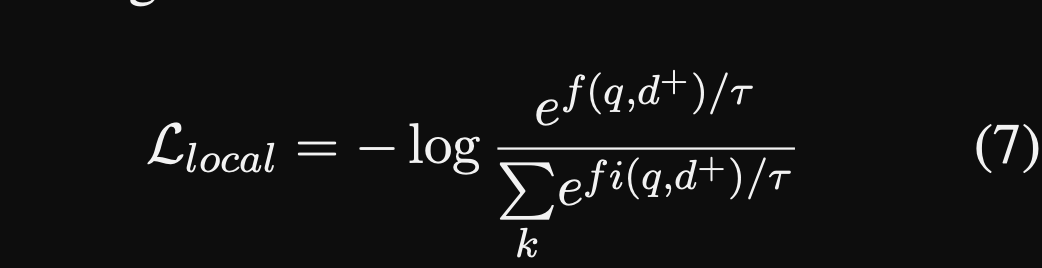
- MVR annealed temperature serves to
stabilize uniformity training- reduce the temperature over the course of training
Results
- MVR results using
8 views- seems like a lot to incur 8x storage cost for a tiny increase in performance
- They could bottleneck the view representations to reduce storage cost
-
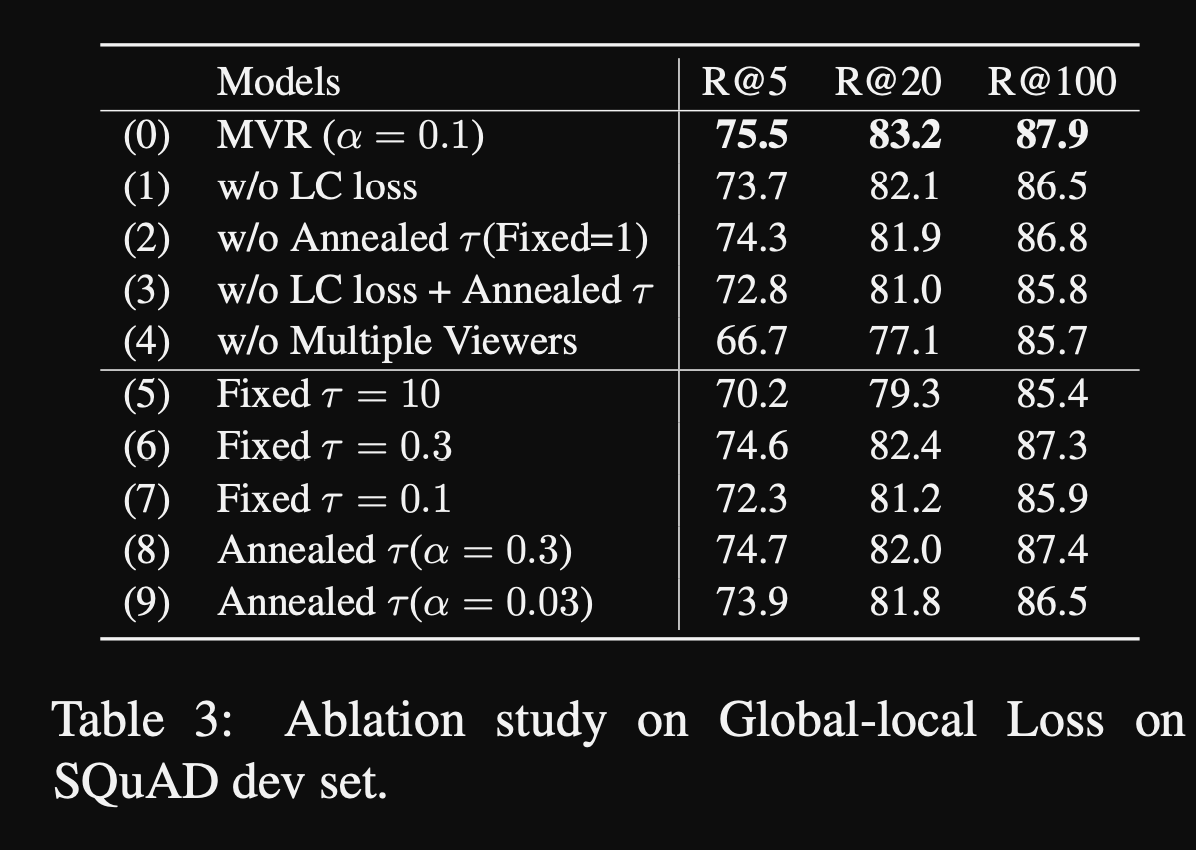
MVR view number ablations
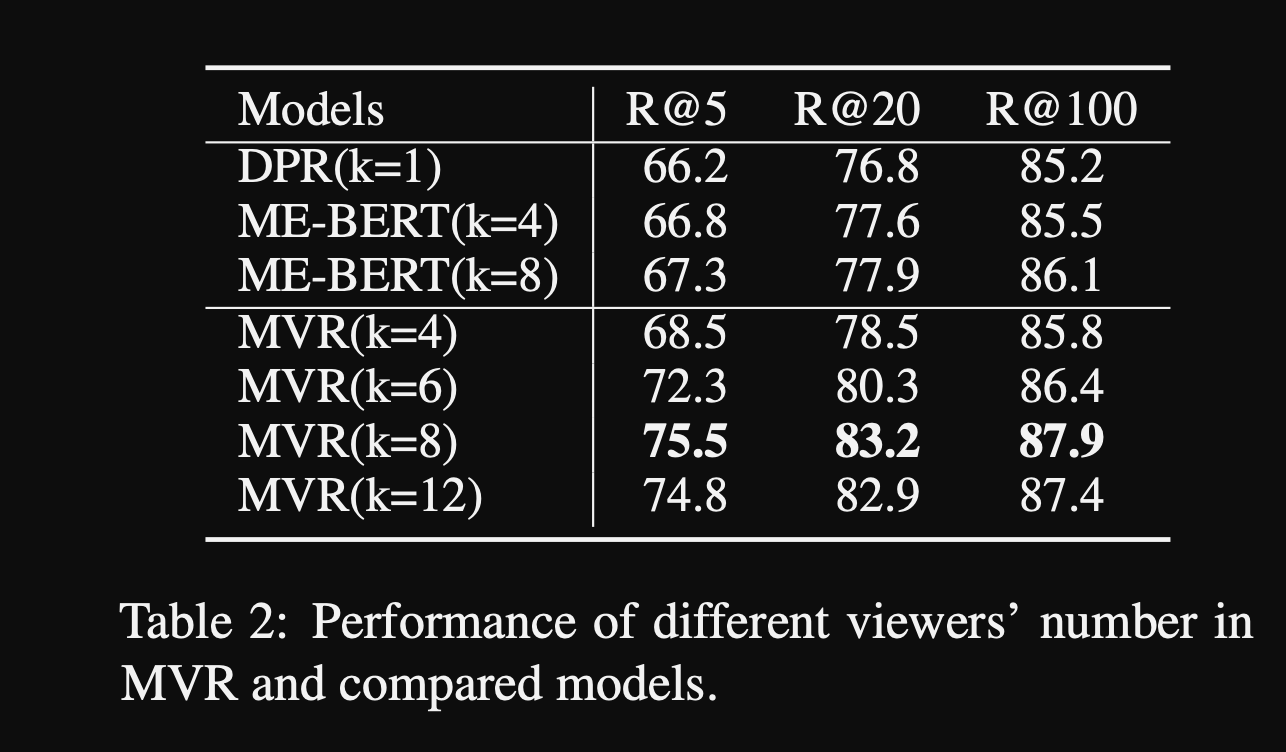
- MVR ablations on loss and annealing
- is relatively sensitive to hyperparameters
- Extensions around MVR
- bottlenecking the view representation
- interpretability on whether different view representations activate on different categories of queries
- whether some objective can be formulated to explicitly encode different structures in each view
- Ablate DPR directly against PolyDPR w/ MaxSim
- How reliant is this method on having multiple queries per document (to encourage development of different views)
- Idea: attention of different view representations: What parts of the document is each view focusing on
Conclusions
In the efficiency statement, they don’t mention the obvious fact that storing multiple view vectors incurs multiple times the storage cost compared to DPR. It would be interesting to develop practical applications around this work. However, only a few vector databases seem to offer indexing multiple vectors per document. The PolyDPR paper uses a similar MaxSim approach over multiple representations for each document.
Reference
@inproceedings{Zhang2022MultiViewDR,
title={Multi-View Document Representation Learning for Open-Domain Dense Retrieval},
author={Shun Zhang and Yaobo Liang and Ming Gong and Daxin Jiang and Nan Duan},
booktitle={ACL},
year={2022}
}