
Mar 18 Research Wrapup
Quick hit thoughts on trending papers?
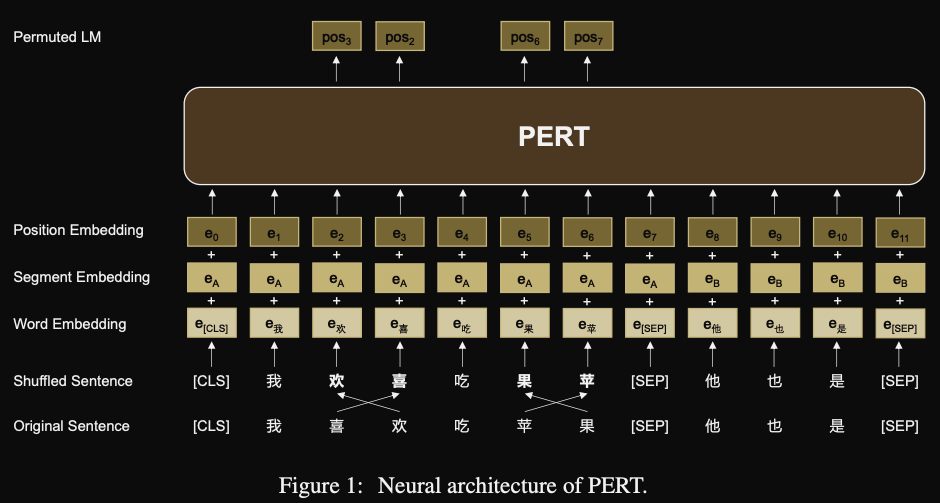
- PERT: PRE-TRAINING BERT WITH PERMUTED LANGUAGE MODEL
- alternative to MLM pretraining task
- task is to recover order of tokens
- note: despite the name, this is NOT the same as the permuted language modeling objective from XLNET
- good results on NLU tasks
- FairLex: A Multilingual Benchmark for Evaluating
Fairness in Legal Text Processing
- Release a multilingual fairness benchmark
- release four pretrained language models
- Efficient Language Modeling with Sparse all-MLP
- facebooks sparse all-MLP architecture gives training efficiency benefits over transformers
- Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
- simple method of averaging finetuned models with different hyperparameters
- no increase in inference cost
- mostly apply to vision and multimodal models
- Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models
- A comprehensive survey of parameter efficient methods
- Also provides some theoretical backing
- This is a research area that I am very interested in
- Deep Continuous Prompt for Contrastive Learning of Sentence Embeddings
- I cover this paper in detail in a separate post
- Very interesting parameter efficient method, however there are a number of issues with this paper
- Does Corpus Quality Really Matter for Low-Resource Languages?
- empirical study shows that NLU performance for low resource language is constrained by quantity rather than quality of text corpora
- GrIPS: Gradient-free, Edit-based Instruction Search for Prompting Large Language Models
- I cover this paper in more detail
- They apply a simple RL technique to generate better instructional prompts