
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
Introduction
-
What is the name of the LayoutLM paper?
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
-
What are the main contributions of the LayoutLM paper?
- combine textual and layout information
- training objectives with masked visual language model and multilabel document classification
Method
- What two types of visual information does LayoutLM seek to take advantage of?
- Document Layout Information
- eg: 2-D coordinates of text tokens can be encoded using positional embeddings
- Visual Information
- words: bold, italic, underlined etc
- Document Layout Information
-
LayoutLM image embeddings come from
Faster RCNN on image cropped to word bounding box -
Layout LM feeds
4 typesof position embeddings into a BERT style model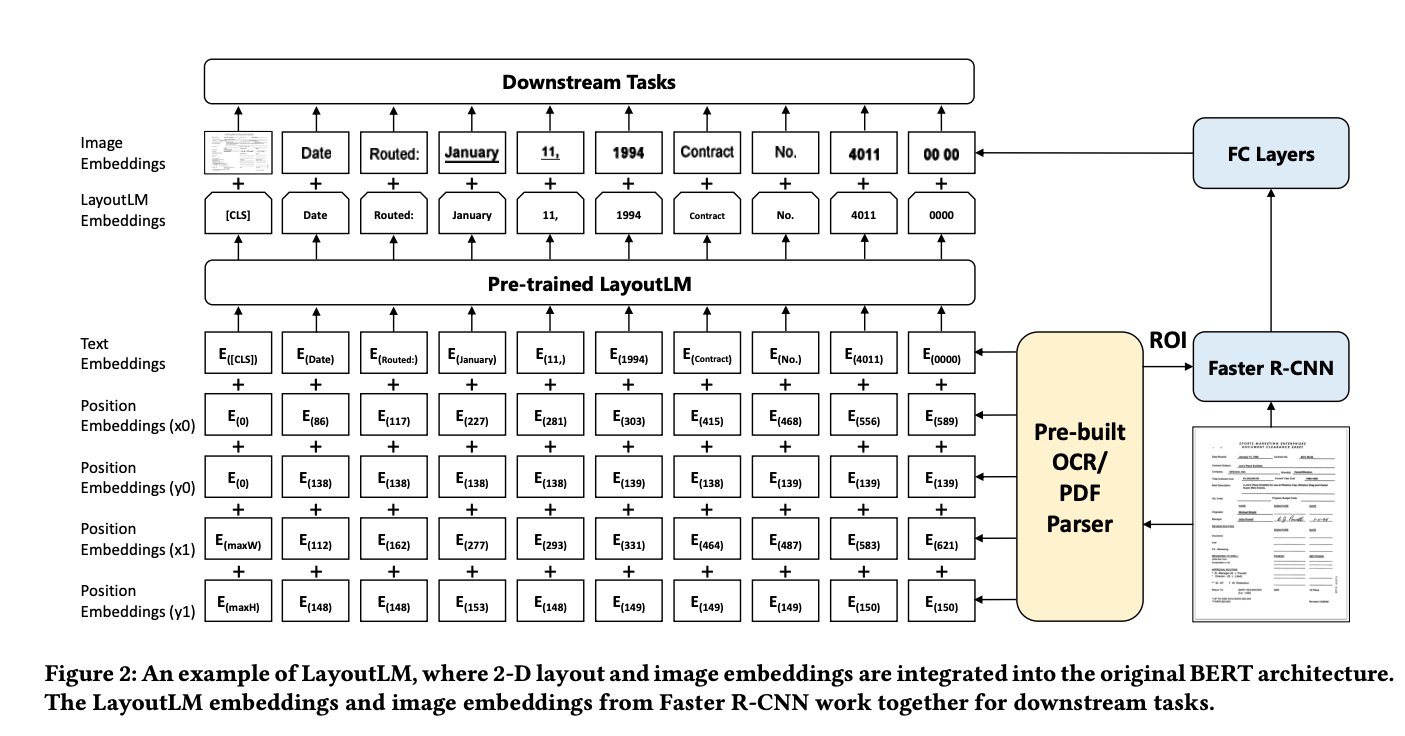
-
LayoutLM pretraining tasks are
masked visual language modeland multilabel document classification - LayoutLM Masked Visual Language Model pretraining masked out token content and aims to predict it using
context and positional encodings- is able to use 2D positional information and rest of document
-
LayoutLM MDC predicts the
document metadata labelsbased on document embeddings -
LayoutLM relies on an effective
OCR engineto get text and bounding boxes - LayoutLM can be finetuned for downstream tasks based on sequence labeling or
whole document embedding
Results
-
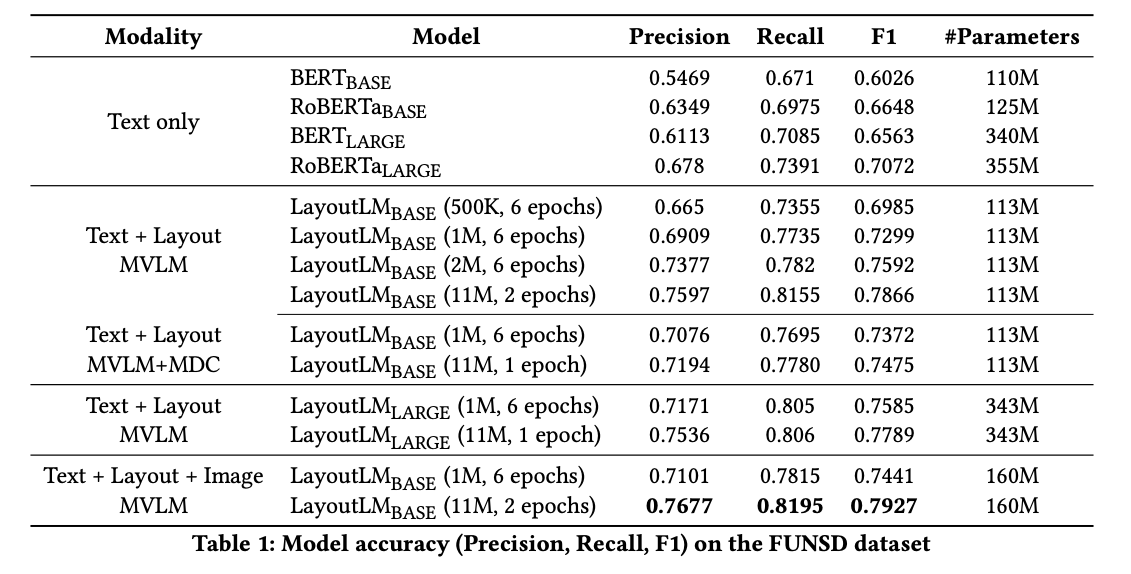
LayoutLM results: FUNSD is a word level form understanding dataset
Conclusions
It’s cool that a transformer can combine different modalities with such a simple method. The positional embeddings must provide a very clear signal for the model to understand the document layout.
Reference
@article{DBLP:journals/corr/abs-1912-13318,
author = {Yiheng Xu and
Minghao Li and
Lei Cui and
Shaohan Huang and
Furu Wei and
Ming Zhou},
title = {LayoutLM: Pre-training of Text and Layout for Document Image Understanding},
journal = {CoRR},
volume = {abs/1912.13318},
year = {2019},
url = {http://arxiv.org/abs/1912.13318},
eprinttype = {arXiv},
eprint = {1912.13318},
timestamp = {Mon, 01 Jun 2020 16:20:46 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1912-13318.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}