
ITERATED DECOMPOSITION: IMPROVING SCIENCE Q&A
Type: Paper
Introduction
-
What is the name of the ELICIT science QA paper?
ITERATED DECOMPOSITION: IMPROVING SCIENCE Q&A BY SUPERVISING REASONING PROCESSES
- What are the main contributions of the ELICIT paper?
- A review of the literature on process supervision, highlighting gaps in workflows and tooling that contribute to making real-world use cases rare
- Iterated decomposition, a human-in-the-loop workflow for developing compositional language model programs
- ICE, an open-source visualizer for language model execution traces
- Case studies that use this workflow to improve performance over baselines on three real-world tasks: (a) extracting placebo information from randomized controlled trials (RCTs), (b) analyzing participant flow in RCTs, and (c) answering questions about natural language processing papers.
- What are some issues with outcome based evaluation of LLMs?
- Process matters for feedback and explainability reasons
- Creates misaligned incentives for agents to be deceptive or manipulative
******Solution:****** process supervision
Related Work
-
What are some previous works on process supervision for LLMs?

-
What is the key idea of the LAMBADA training paper?
apply backward-chaining to simple logic tasks, starting with a goal proposition and recursively decomposing it into sub-goals until the sub-goals can be proved or disproved
-
How can we recursively use language models to generate summaries of large texts?
**Recursively Summarizing Books with Human Feedback - Open AI
- They use LMs to summarize small sections of the text and then recursively summarize these summaries to produce a summary of the entire text.
- They show that recursive summarization improves the quality and coherence of the summaries, and enables human feedback and evaluation
- How does the RE3 model propose to generate long stories with LLMs?
- first create a story plan, generating passages by prompting a model with contextual information from the plan and the current story state, and then revising the passages by reranking and editing them
- How are LLMs and tools used in the REACT paper?
- interleaves generating chain-of-thought reasoning and actions pertaining to a task (e.g., search, lookup)
- The main idea of **Program-aided Language Models** is to
offload computation to a python interpreter- LLM writes reasoning with python code
- Answer is given by executing code
- Improves over PALM COT
- What is the main idea of the Maieutic prompting paper?
- tree of explanations from possibly unreliable COT
- inference is a satisfiability problem over these explanations and their logical relations
- What are the main ideas of the decomposed prompting paper?
- decompose to subtasks
- recurse to shared library of task optimized LLMs
- What are the main ideas of the ThinkSUM paper?
- THINK: parallel LLM inference over phrases from prompt
- SUM: slow probabilistic inference: aggregate to final answer
- potentially for more flexibility and interpretability
- What are the 3 steps for multihop QA employed in the RERC paper?
- ************Relation Extractor:************ decompose input into multiple subquestions
- **Reader:** answer the subquestions
- ******Comparator:****** summarization and aggregation to get the correct answer
- What are some conclusions of previous work on outcome based vs processed based LLM finetuning?
- process based improves results
- requires more label supervision
- application is math word problems
- What is meant by the term compositionality gap?
- fractions of questions LLM answers wrong when it answers all the subquestions correctly
Method
-
Iterated Decomposition includes a
Human in the Loop - What are the main high level steps in iterated decomposition?
- Start with a **************minimal decomposition**************
- break tasks into subtasks that can be performed by an LLM
- ex: finding the section of a scientific study that lists the placebo
- Apply Decomposition to the test inputs with multiple gold standard answers
- Evaluate results automatically or manually
- Could Score with an LLM → AIF
- Identify failure occurrences in the reasoning trace
- Improve Failing Components with Further Decomposition
- COT
- Retrieval
Can iterate with HITL several times
- Start with a **************minimal decomposition**************
-
Ex LLM execution trace in ICE
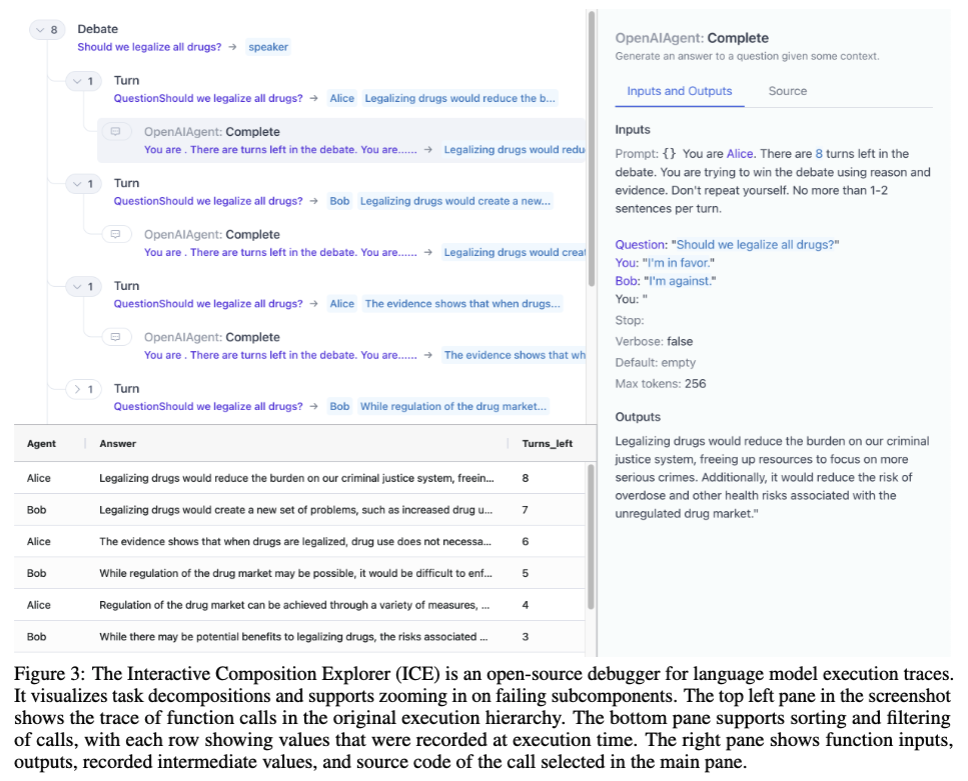
-
Example questions to answer with iterated decomposition?
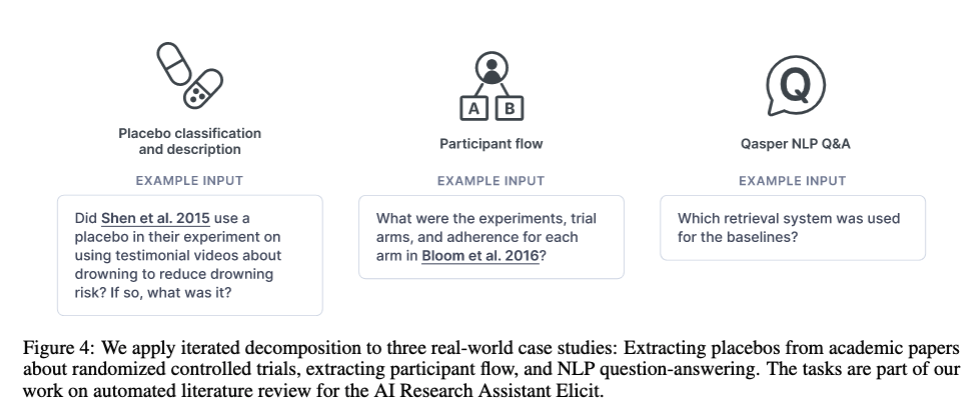
- Example research ****process**** for a researcher to follow
- What are the RCTs that are potentially most relevant to answering my research question
-
For each RCT:
(a) Does this study actually address my research question?
(b) What is the risk of bias? Can I take the findings at face value, or do I need to discount it or ignore it?
- What does the aggregate of RCTs, weighted by evidence quality, say about my research question?
****************************************How can we train an LLM to decompose a problem and follow these steps****************************************
Placebo Case Study
-
How does the baseline question answering system work in Elicit?
**************Select then generate**************
- rank paragraphs against question with MonoT5
- feed to top ranking paragraph into GPT-Davinci-002 with the following prompt
Answer the question " " based on the excerpt from a research paper. Try to answer, but say "The answer to the question is not mentioned in the excerpt" if you don't know how to answer. Include everything that the paper excerpt has to say about the answer. Make sure everything you say is supported by the excerpt. The excerpt may cite other papers; answer about the paper you're reading the excerpt from, not the papers that it cites. Answer in one phrase or sentence:- Note: the prompt allows for negative answers and would require an instruction tuned model
-
Elicit better decomposition process to look for a placebo seems to be
inspired by human process- Classify based on trial arms
(a) What were the trial arms?
i. Rank paragraphs by relevance to this question through pairwise comparisons
ii. Answer based on the most relevant paragraphs
(b) Describe each trial arm: Rank and Answer
(c) Do any of the arms look like placebos?
(d) If so, could participants tell which arm they were in? (If so, there’s not really a placebo.)
- Classify based on each paragraph
(a) Was there a placebo, according to each paragraph?
(b) Aggregate answers from paragraphs
- Ensemble the classification based on trial arms and paragraph
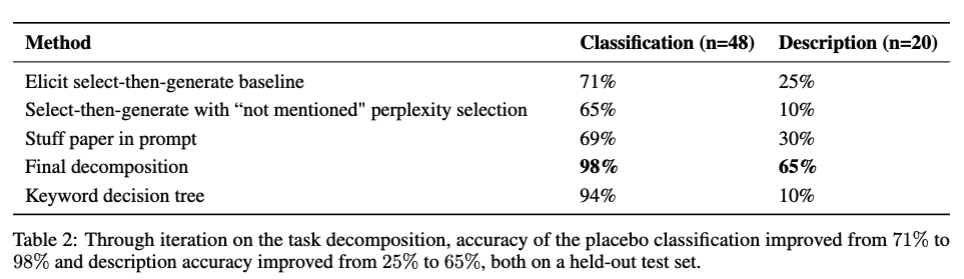
- increase their accuracy to 98%
- seems to incur an $O(n^2)$ cost in terms of pairwise paragraph rankings
-
ELICIT results on placebo tasks with baselines
- relatively small sample size
RCT Participant Flow
- ELICIT method for RCP participant flow
- evaluate whether each gold standard arm is present
- classify adherence mentioned vs no adherence

- How did Elicit go about a diagnosis workflow for RCT trial arm adherence?
- id that 80% of errors were false negatives
- false negatives came from MonoT5 selecting the wrong paragraph
- oracle: accuracy rose to 77%
- therefore should focus on increasing ranking accuracy
**********note: How could we use an LLM to automate this kind of error analysis and propose avenues for improvement**********
- ELICIT workflow for few shot finetuning an adherence paragraph classifier uses
TFew- ensemble multiple weak classifiers
- hard label positives and keep hard negatives
- do few shot finetuning
-
ELICIT Tfew finetuning is done with a
zero shot promptincluded in finetuning data
- What are some characteristics of problems where this kind of few shot finetuning should be considered?
- Task is hard but data is relatively easy to collect
- Where a smaller cheaper classifier is desired
- ELICIT classifiers could be served as a
swarm of classifiers with mixed task batches- mixed task batches or in batch parallel computing is a key feature of parameter efficient methods
- Could have many classifiers deployed at once and have an LLM decide which one to use
- Besides finetuning classifiers what other approaches did elicit take towards improving selection accuracy?
- prompt engineering
- zero shot perplexity classifier
- pruning
- ELICIT zero shot perplexity classifier scores paragraphs by the
inverse perplexity of excerpt not found answer- can rank each paragraph with this score
- better results for subtle semantic differences

- Found that including multiple paragraphs above some threshold improves results
- note that this is a full GPT-3 call per paragraph and thus more expensive
- What is meant by the sentence decontextualization task in NLP?
- taking a sentence together with its context and rewriting it to be interpretable out of context, while preserving its meaning.
- Elicit approach improving generation for trial arm adherence detection involved
few shot demonstrations in prompt
Case Study: QASPER NLP question answering
-
QASPER dataset consists of questions about
NLP papers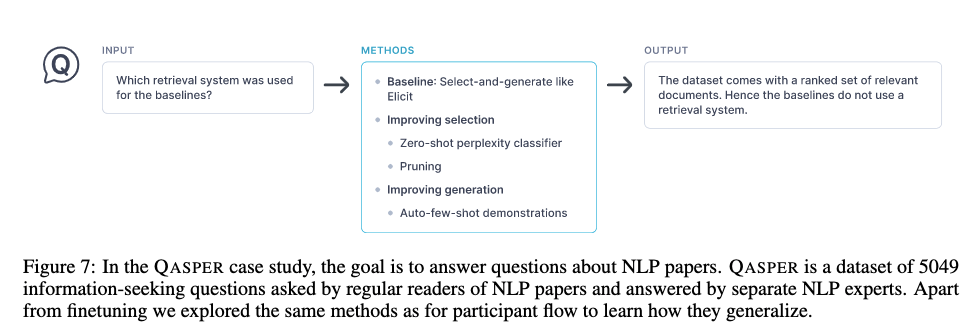
-
ELICIT decompositions results for select then generate
- seems like using a larger model with perplexity is a lot better than smaller cross encoder rerankers

Conclusions
- What are some proposed followup steps to build on Elicit’s decomposition work
- Increased iteration speed. Before full automation, we expect to be in the world where human programmers can automate novel complex tasks by improving a task decomposition with many iterations per day.
- Complex decompositions. Essentially all decompositions in prior work and to some extent also in our case studies are fairly simple, even when they make hundreds of language model calls.
- To accomplish 1 and 2, more sophisticated developer tools that make it faster to go from overall result to the sources of errors, to proposals for how to address them.
- Making the dev tools in 3 machine-accessible so that the diagnosis and improvement steps can be learned by LMs.
- Reducing the boundary between task design and execution, so that decomposition, debugging, and iteration can happen at runtime as models execute complex tasks.
- Distillation and other ways to reduce cost of complex decompositions, so that decompositions are more cost-competitive with end-to-end execution
Overall this was a very good read in that it 1) contextualized a lot of the recent literature around compositional problem solving using Language Models. and 2) provided a solid framework with examples around how to think about decomposition. It makes sense for Elicit to start by targeting semistructured tasks with fairly regular structures such as placebo classification before moving on to more complex compositional tasks. The tool is already extremely useful for the researchers but I expect the approach to iteratively improving systems to be even more valuable in the future.
Reference
@article{Reppert2023IteratedDI,
title={Iterated Decomposition: Improving Science Q\&A by Supervising Reasoning Processes},
author={Justin Reppert and Ben Rachbach and Charlie George and Luke Stebbing and Ju-Seung Byun and Maggie Appleton and Andreas Stuhlm{\"u}ller},
journal={ArXiv},
year={2023},
volume={abs/2301.01751}
}s