
Domain-matched Pre-training Tasks for Dense Retrieval
Introduction
-
What is the name of the DPR PAQ paper?
Domain-matched Pre-training Tasks for Dense Retrieval
FAIR
- What are the main contributions of the DPR PAQ paper?
- pretraining tasks specifically for IR
- strong performance on benchmark neural IR evaluation tasks
- experiments with retrieval models at different scales
- The PAQ dataset consists of
65 million synthetic question answer pairs- extracted from wikipedia based on models trained on natural questions
- can be used for passage retrieval training
- DPR-PAQ trains on reddit data which are
post -comment pairs- useful for modeling dialogue
- Why might we want to use alternative evaluation metrics for training neural information retrievers?
- expensive to reindex entire corpus
- alternatives:
- validation cross-entropy loss
- in-batch accuracy
- MRR on an in batch corpus
Method
- DPR- PAQ finetunes on end tasks for up to
40 epochs- For BERT and DeBERTa models, we use [CLS] token directly as representation, whereas for RoBERTa we add a linear projection of the same size and an additional layer normalization
-
DPR-PAQ scaling results: largest
deBERTa modeldoes best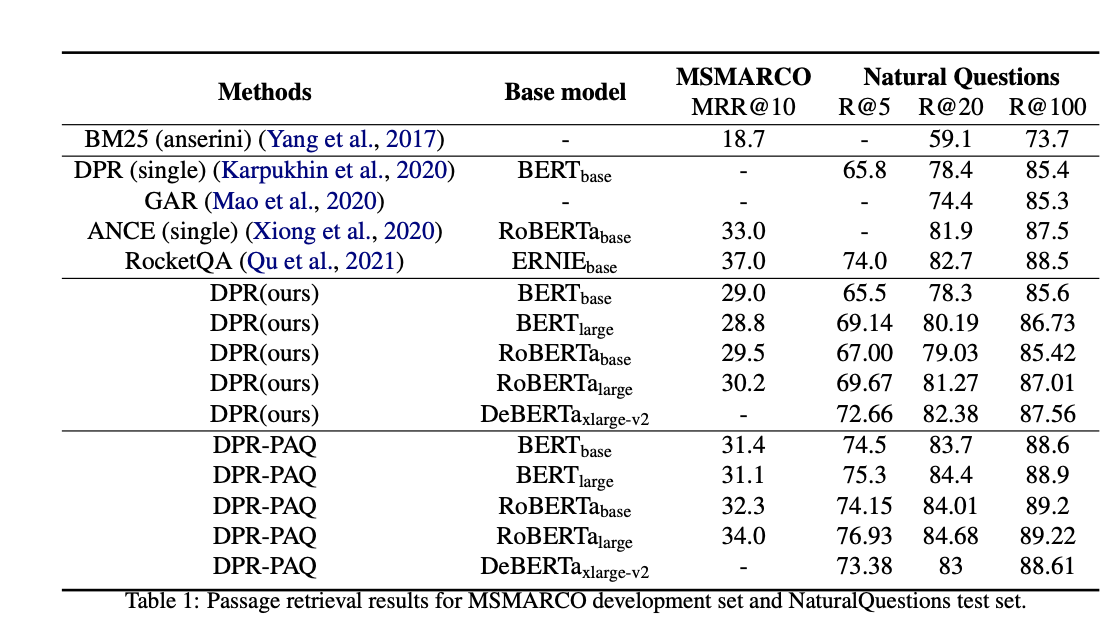
Results
-
DPR-PAQ results scaling with dataset size
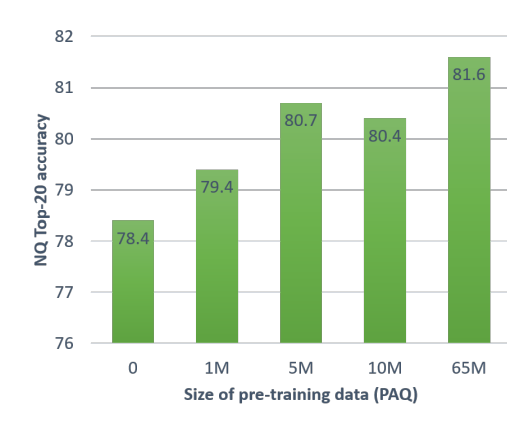
Conclusions
- As they mention zero shot performance is likely due to domain overlap
Reference
@article{DBLP:journals/corr/abs-2107-13602,
author = {Barlas Oguz and
Kushal Lakhotia and
Anchit Gupta and
Patrick S. H. Lewis and
Vladimir Karpukhin and
Aleksandra Piktus and
Xilun Chen and
Sebastian Riedel and
Wen{-}tau Yih and
Sonal Gupta and
Yashar Mehdad},
title = {Domain-matched Pre-training Tasks for Dense Retrieval},
journal = {CoRR},
volume = {abs/2107.13602},
year = {2021},
url = {https://arxiv.org/abs/2107.13602},
eprinttype = {arXiv},
eprint = {2107.13602},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-13602.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}