
Document-level Relation Extraction as Semantic Segmentation
Introduction
-
What is the name of the DocuNET paper?
Document-level Relation Extraction as Semantic Segmentation
- What are the main contributions of the DocuNET paper?
- treat document level relation extraction as a semantic segmentation task
- take advantage of global dependency among relational triples
- leverage U-NET inspired semantic segmentation architecture
-
Document level relation extraction extracts relation information from
multiple sentences
- What are some difficulties with document level relation extraction?
- subject and object entities may not appear in the same sentence
- Previous approaches for document level RE include
graph based and transformer model based
Method
- DocuNET leverages a
entity levelrelation matrix- each cell is a relation type
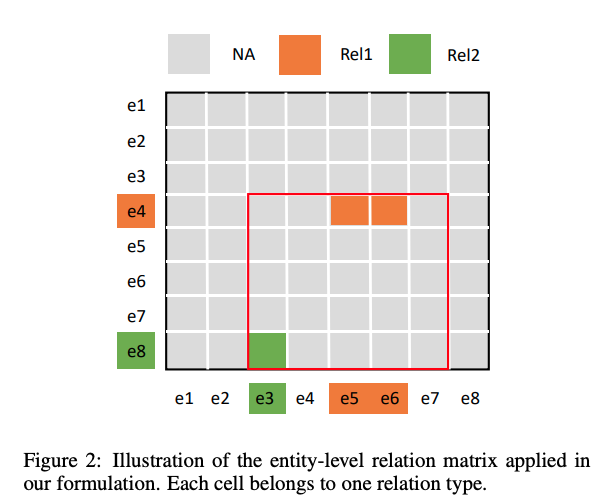
-
DocuNET problem statement: output matrix is
n x n giving each entity relation -
DocuNET encodes a document using a transformer with special
entity mention boundary tokens - DocuNET embeds longer documents using dynamic
window pooling- average embeddings of overlapping tokens of different windows\
- DocuNET entity-entity relevance vector from similarity method is concatenation of
element wise similarity, cosine similarity and bilinear similarity- based only on embedding for each entity
- alternative to a content based method
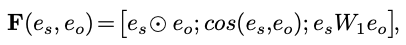
-
DocuNET content based strategy leveraging
entity based attentionand the globaldocument embedding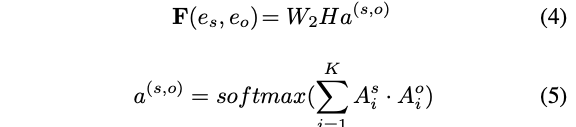
-
DocuNET UNET architecture
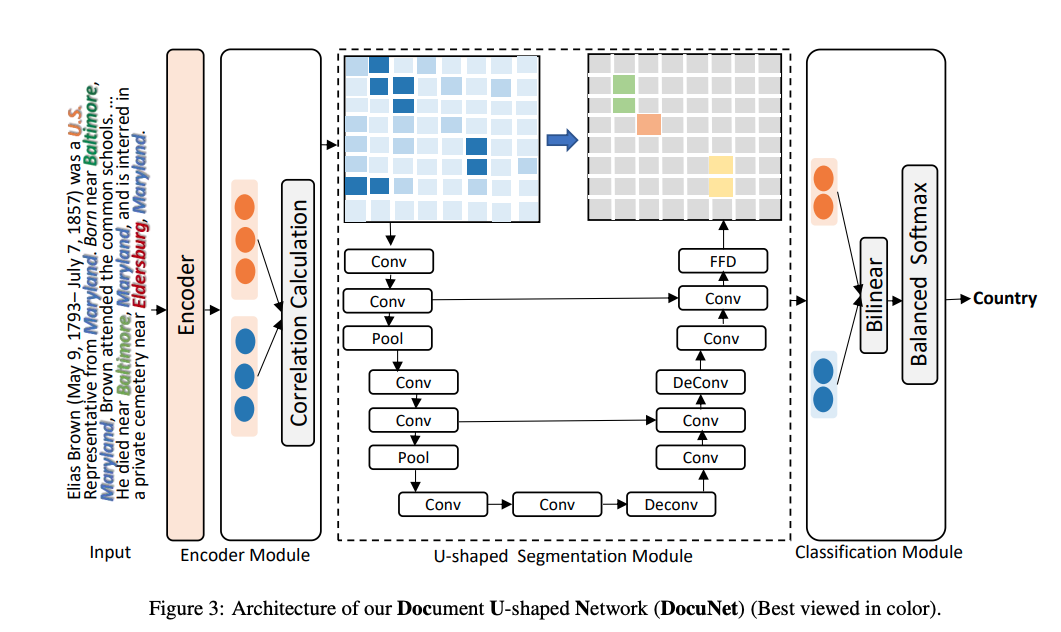
Results
-
DocuNET case study
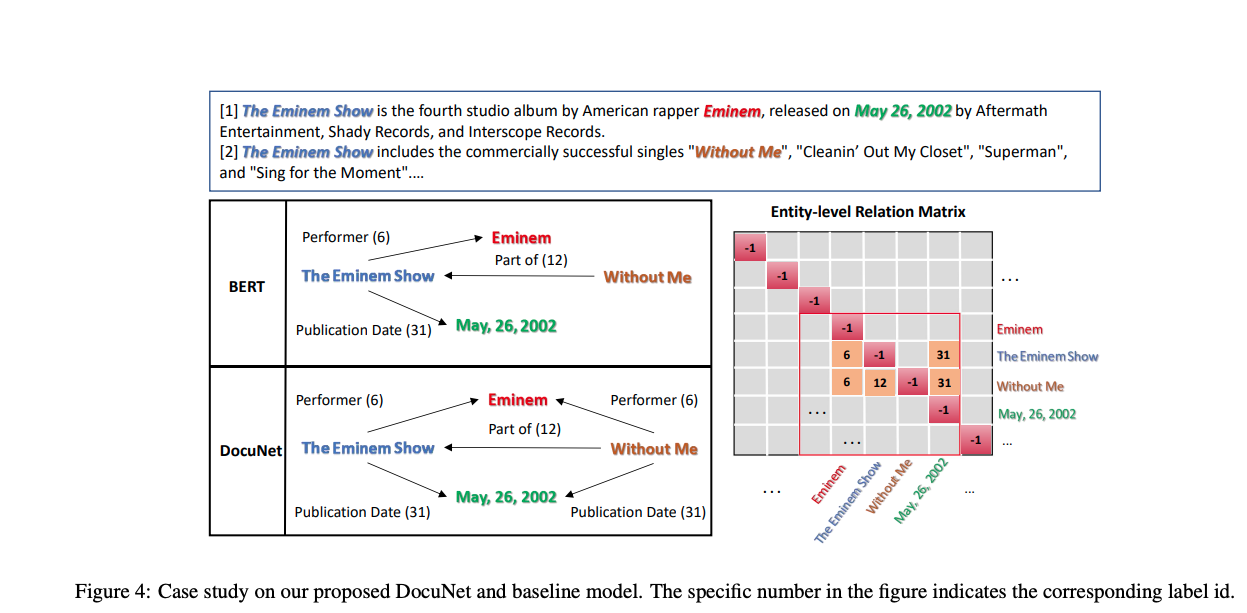
-
DocuNET strong results on Biomedical datasets
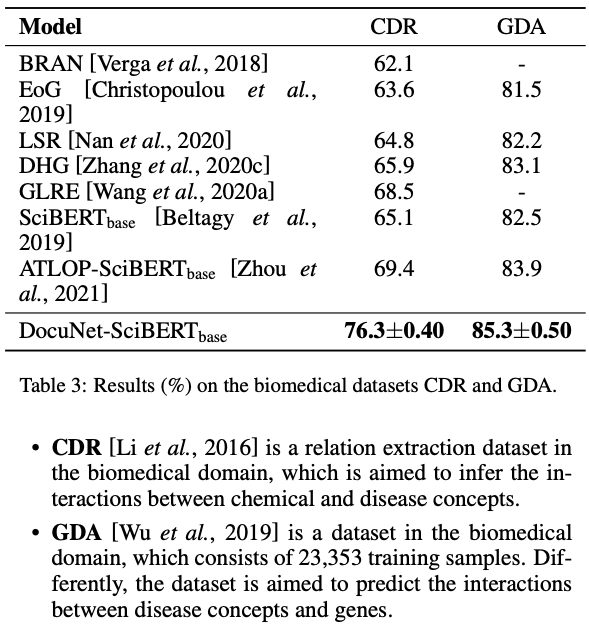
-
DocuNET results on DocRED
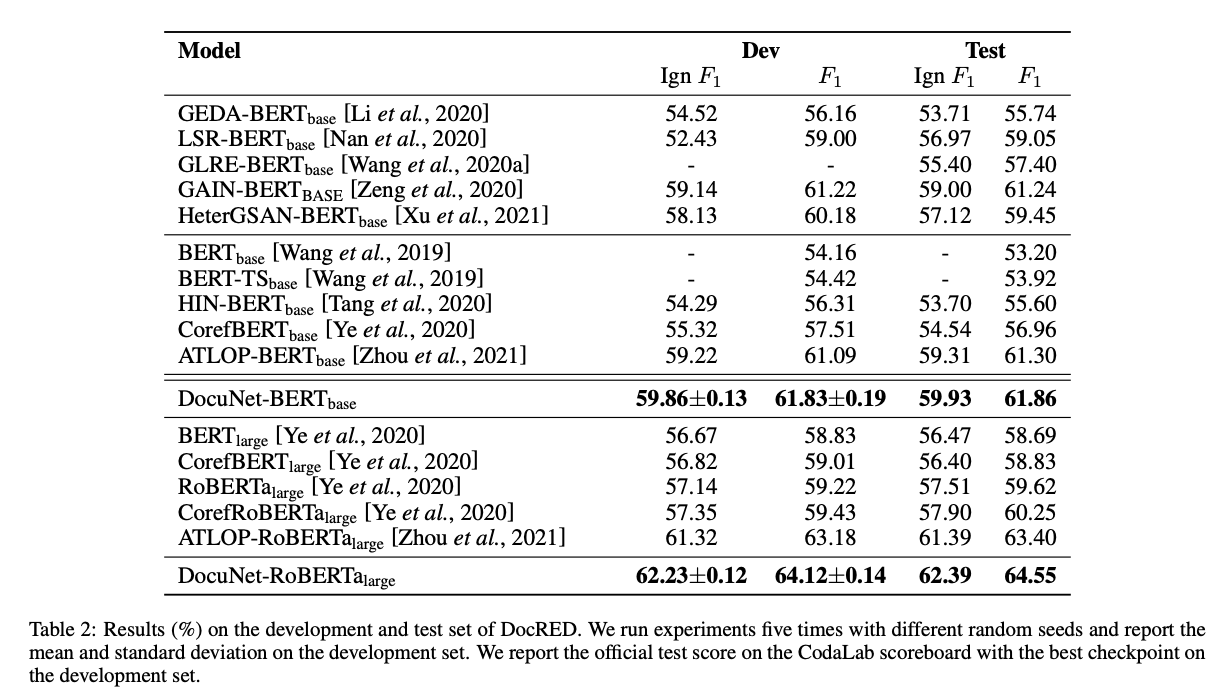
Reference
@misc{https://doi.org/10.48550/arxiv.2106.03618,
doi = {10.48550/ARXIV.2106.03618},
url = {https://arxiv.org/abs/2106.03618},
author = {Zhang, Ningyu and Chen, Xiang and Xie, Xin and Deng, Shumin and Tan, Chuanqi and Chen, Mosha and Huang, Fei and Si, Luo and Chen, Huajun},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Document-level Relation Extraction as Semantic Segmentation},
publisher = {arXiv},
year = {2021},
copyright = {arXiv.org perpetual, non-exclusive license}
}