
DocFormer: End-to-End Transformer for Document Understanding
Introduction
-
What is the name of the DocFormer paper?
DocFormer: End-to-End Transformer for Document Understanding
AWS AI
- What are the main contributions of the DocFormer paper?
- novel multimodal attention layers to fuse information
- 3 unsupervised pretraining tasks
- Can be trained end 2 end
- SOTA performance on 4 VDU tasks
- Does not rely on custom OCR
-
LayoutLMv2 improved upon layoutLM by
treating visual features as separate tokens -
Conceptual styles of multimodal transformer encoder models include Joint Multimodal, TwoStream multimodal, Single Stream Multimodal and
Discrete Multimodal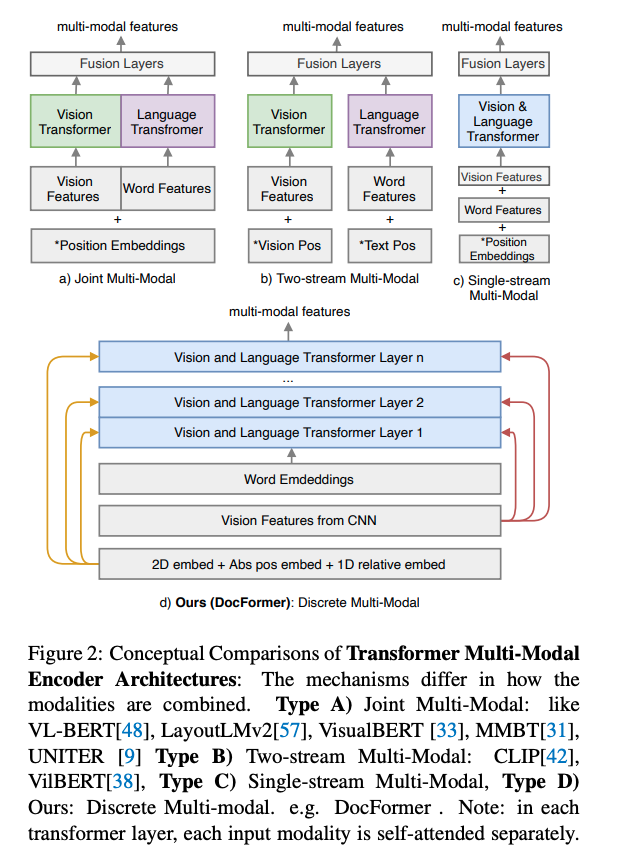
-
Joint Multimodal architectures: vision and text features are
concatenated in a single sequence - Two Stream Multimodal architectures: each modality is modeled with a
separate model- examples: CLIP, VILBERT
-
Two Stream Multimodal architectures have the disadvantage that text and image
only interact at the endwhich can be mitigated byearly fusion approaches - Single Stream Multimodal combines vision features with text as
tokens- not a well-motivated approach
- Docuformer is an example of
discrete multimodalmultimodal architecture- passes spatial and visual features to each transformer layer
Method
- DocFormer extracts visual features using a
Resnet 50- flatten features to 768 x 512 representation
- DocFormer text spatial features are
top left and bottom right coordinates as well as bounding box height and width- also euclidean distance to bounding box to the right
- absolute 1D position encodings (order of text)
Visual Features have separate spatial embeddings
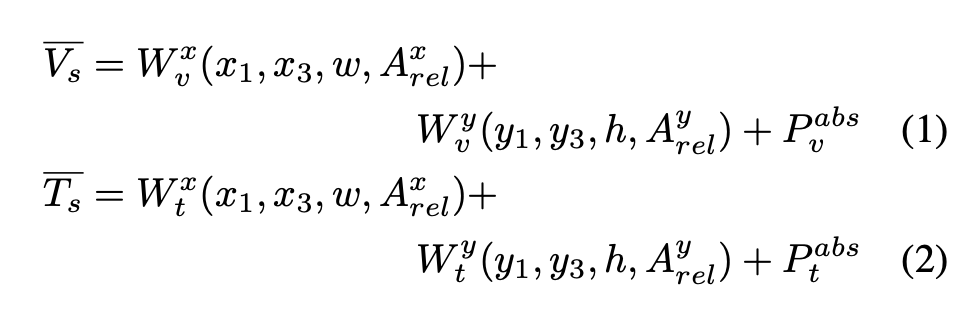
- DocFormers main novel feature is a
multimodal self attentionlayer- Visual features, Text features, and spatial encodings for each are 512 x 768 dimensional inputs
- Encoder only Transformer will generated combined representation
- Multihead scaled dot product attention
- spatial weights W_s are shared between visual and text features
- Visual Features:
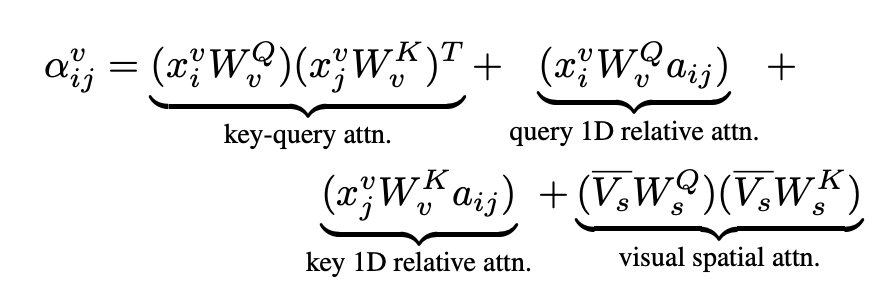
- DocFormer visual representation is passed to transformer
at every layer- visual representation does not evolve across layers
- makes this information fully accessible across layers:
- they call this an
information residual connection
- they call this an
- Shown to lead to better
cross modality feature correlation
- DocFormer pretraining tasks are:
multimodal masked language modelinglearning to reconstructandtext describes image- MMLM: mask out text token
- visual features for bounding box are not masked
- Masked Vision TokeN: feed through encoder to get reconstructed image and use autoencoding loss
- smooth L1 loss
- Text Describes Image:
- binary classification to whether text describes a document image
- use global pooled multimodal representation
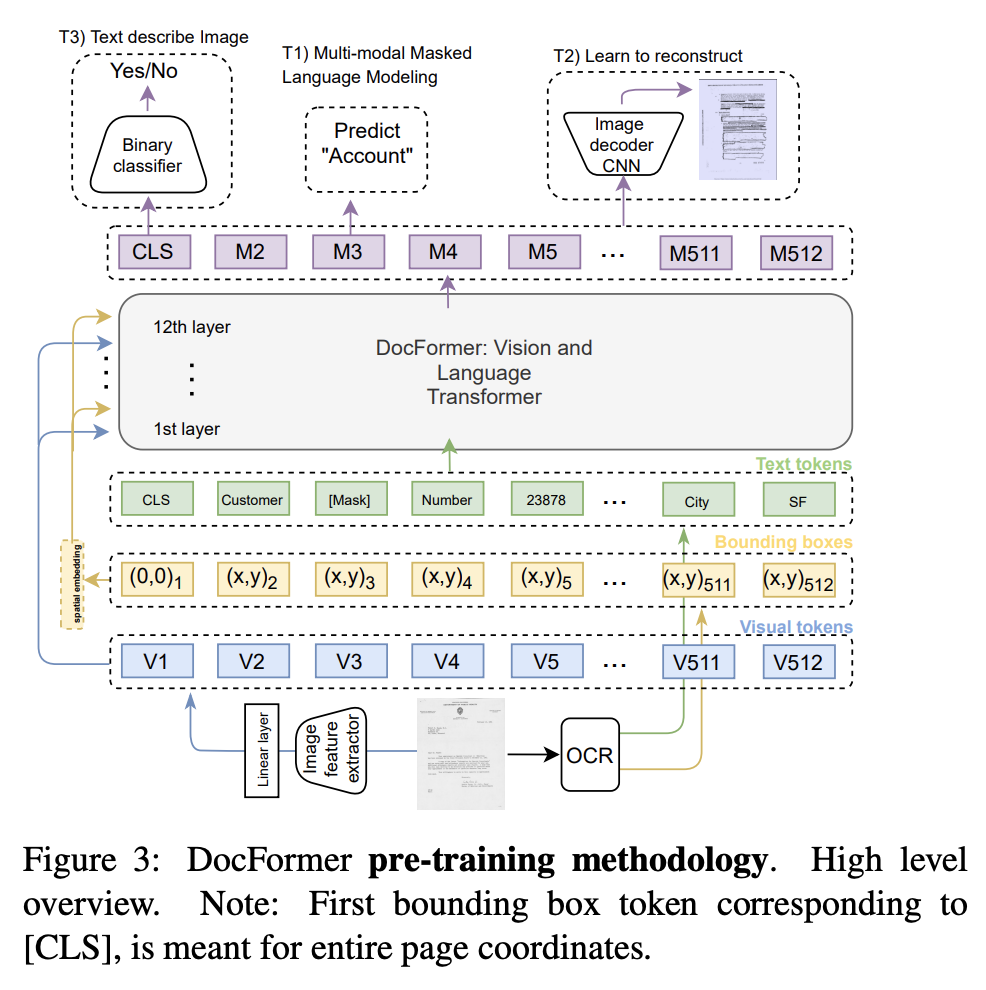
- MMLM: mask out text token
Results
- Docformer beats
larger modelson FUNSD- Note: FunSD has very few samples for finetuning
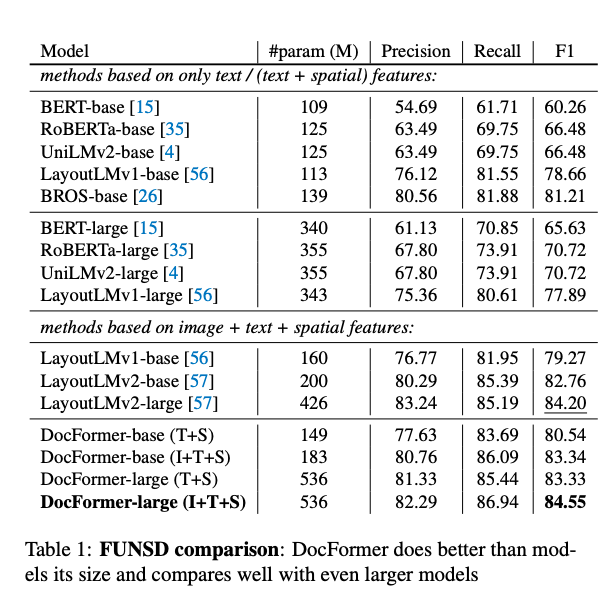
-
DocFormer FUNSD performance vs pretraining data
more data helps
Reference
@misc{https://doi.org/10.48550/arxiv.2106.11539,
doi = {10.48550/ARXIV.2106.11539},
url = {https://arxiv.org/abs/2106.11539},
author = {Appalaraju, Srikar and Jasani, Bhavan and Kota, Bhargava Urala and Xie, Yusheng and Manmatha, R.},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {DocFormer: End-to-End Transformer for Document Understanding},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution 4.0 International}
}@misc{https://doi.org/10.48550/arxiv.2106.11539,
doi = {10.48550/ARXIV.2106.11539},
url = {https://arxiv.org/abs/2106.11539},
author = {Appalaraju, Srikar and Jasani, Bhavan and Kota, Bhargava Urala and Xie, Yusheng and Manmatha, R.},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {DocFormer: End-to-End Transformer for Document Understanding},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution 4.0 International}
}