
Dense Passage Retrieval for Open-Domain Question Answering
Introduction
-
What is the name of the DPR paper?
Dense Passage Retrieval for Open-Domain Question Answering
FAIR
- What are the main contributions of the DPR paper?
- original dense retrieval outperforms TFIDF/BM25
- simple finetuning can improve dense retrieval
- higher retrieval precision leads to higher QA accuracy
- What 2 weaknesses with the ORQA approach does the DPR paper identify?
- ICT pretraining is computationally expensive
- Context encoder is not finetuned
Method
- The DPR method uses
separate BERT encodersfor query and passages- uses the dot product between them
- The DPR objective is basically
NCE loss- they use in batch negatives
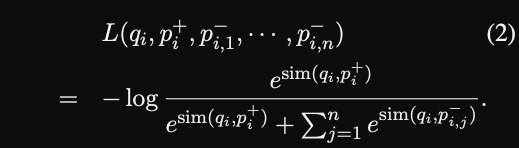
- DPR training considers
3different types of negatives- Random: any random passage
- BM25: top passages returned by BM25 that do not match question (more difficult set of negatives to predict)
- GOLD: positive passages paired with other questions in the training set
Results
-
DPR results: outperforms
BM25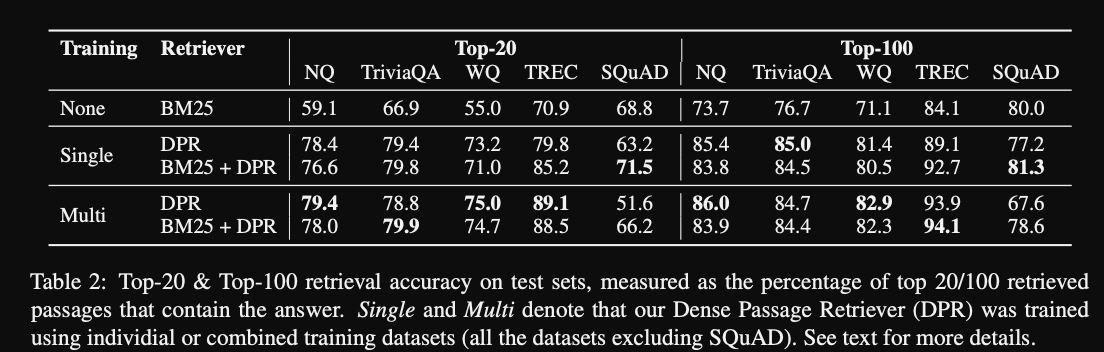
-
DPR results performance scales with
number of training passages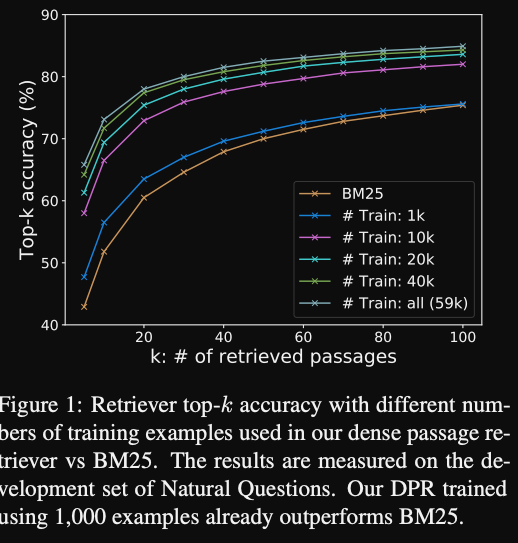
-
DPR results
dot productand L2 distance outperform cosine similarity- dot product is cheapest computationally
Conclusions
This was a basic paper on using BERT for dense passage retrieval. Notable design decisions were having a separate query and passage encoder and using dot product similarity.
Reference
**@article{karpukhin2020dense,
title={Dense passage retrieval for open-domain question answering},
author={Karpukhin, Vladimir and O{\u{g}}uz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau},
journal={arXiv preprint arXiv:2004.04906},
year={2020}
}**