
Decoder Inference Optimization
Introduction
Transformer-based decoder-only models have important applications in natural language processing, particularly for fluent text generation. Practical use cases for such models depend on efficient inference for the purposes of 1) reducing latency for user experience and 2) mitigating the deployment cost of large language models. In this paper, we survey the recent advances in inference optimization for decoder-only models with a focus on GPT2. We categorize the inference optimization techniques into several categories namely run time optimization, architectural model changes, and distillation. We discuss the advantages and disadvantages of each technique and propose a roadmap for the implementation of techniques. Finally, we discuss a real-life bag of tricks for deploying such models.
Optimization Techniques
The two most basic techniques to improve autoregressive inference without changing the model outputs are K-V caching and graph optimization. Key-value caching involves storing the previous Key and Value pairs during transformer inference and reusing them to generate the next token. Graph optimization, on the other hand, involves analyzing and modifying the computation graph of the model to make it more efficient. This can include techniques such as fusion and kernel replacement. Operator fusion involves combining multiple operations into a single operation that can be performed in a single computation cycle. Other graph operations can be replaced with optimized kernels for faster execution. One newer optimization for the attention operations in transformer models is Flash attention (Dao 2022). Flash attention fuses the softmax and matrix multiplication operation in attention to avoid being bottlenecked by GPU memory.
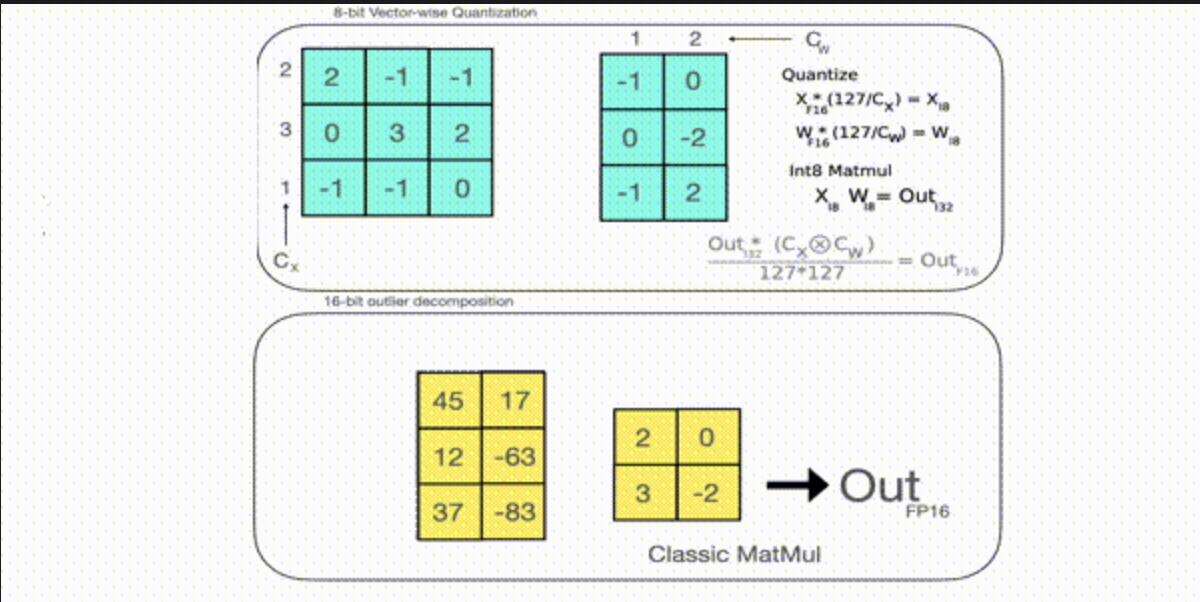
Further techniques require modifications to the actual mode such as quantization, pruning, and knowledge distillation. Quantization reduces inference computation by lowering the precision of model parameters and activations, typically from 32-bit floating point to 16-bit floating point or even Int8 or Int4. This can significantly reduce the amount of memory required to store the model and the amount of time required to perform computations, but can also introduce some loss of accuracy.
Pruning involves removing unnecessary parameters or operations from the model, which can reduce the number of computations and the size of the model, but again can also impact accuracy. There are several methods for pruning a model, including weight pruning, unit pruning, and structured pruning.
Knowledge distillation involves training a smaller model to mimic the behavior of a larger, pre-trained model (Hinton 2015). The smaller model, called the “student,” is trained to produce the same output as the larger model, or “teacher,” on a given dataset. By using the output of the teacher model as a target, the student model can learn to perform the same task more efficiently.
Discussion
These techniques have various pros and cons and can be used in combination with one another (Movva 2022). Overall in comparison with naive, dense, PyTorch eager model inference a good suite of optimizations can reduce inference cost an order of magnitude or more. K-V caching and graph optimizations as well as flash attention are standard techniques that should not change the model outputs at all and thus can be applied at no cost. Optimized runtimes for transformer models include TensrorRT, OpenVino, and Triton inference server. Other optimization techniques change the model output and thus involve additional work to implement and verify the optimized model outputs. In general FP-16 16-bit inference is stable. Lower precisions such as Int8 and Int4 may require more specialized techniques as well as Quantization Aware Training (Dettmers et al, 2022). In addition, models can be run with TF32 enabled on ampere GPUS to get a significant speedup. Pruning reduces the number of parameters in the model but can require additional computation to select the parameters to prune and may require specialized hardware for inference. Knowledge distillation has a significant advantage in that the smaller student model can be more efficient. However, it is involved in terms of the training setup needed to distill from the teacher model.
Roadmap
The actual optimizations relevant to a production system depend on a number of factors including the latency and throughput demands, the number of models, and the availability of engineering resources. Generally, the key consideration is to mine the low-hanging fruit first to get the most per engineering hour invested and work on additional optimizations as needed. Given the rapid development of open-source services, it also makes sense to maintain flexibility in order to adapt to new tools as they become available. Concretely useful packages include NVIDIA’s faster transformer and Huggingface Optimum. Optimization targets should be selected according to business requirements. For example, setting a minimum latency to return results to a user vs throughput optimizations to save costs on batch processing jobs. Minimally, models should be run with key-value caching on an optimized runtime. The Triton inference server provides such a service along with dynamic batching. Next, if more speedups are needed FP16 should be used. . Int8 can over additional speedup but the fastest static quantization approaches require additional computation. Depending on the number of models and their serving cost, it may be worth it to set up a pipeline for lower levels of quantization. If the serving costs are high enough for a single model it might be worth outsourcing model inference optimization to specialized providers such as Stochastic.ai. Such companies specialize in inference optimization and thus can likely provide the best efficiency.
Advanced Techniques
Useful Deployment Techniques
Quick hit optimizations for useful NLP generation systems: These techniques can give you quick and easy improvements for your model deployments.
- truncate obviously hallucinated LM output: If a language model looping and hallucinating repeated text we can truncate the language model output
- cache generations for the most popular inputs
- Optimize your temperature top p repetition penalty and number of beams parameters
- If serving a very large number of requests set a target GPU utilization below 90% to allow time for autoscaling to kick in
Large Language Model Inference
Larger language models beyond GPT2 require multiple GPUS. Scaling beyond a single GPU presents an additional set of challenges inherent to splitting the model across multiple GPUs. Frameworks that support multiple GPUs include Deepspeed and Megatron as well as HuggingFace Accelerate.
Multitask Model Serving
Parameter-efficient finetuning methods only update a fraction of a language model’s parameters during finetuning. In addition to memory efficiency, methods such as prompt tuning have the key property that they allow for in-batch parallel computing for different finetuned models (Ding et al 2022). Effectively, they can allow the same service to serve efficiently serve dozens of models at one time (Tang 2022).