
Compacter
Intro
-
What is the name of the compacter paper?
COMPACTER: Efficient Low-Rank Hypercomplex Adapter Layers
- Compacter paper was written by
Rabeeh Karimi MahabadiJames HendersonSebastian Ruder
- Compacter paper was written by
The main idea of the compacter paper is to factor adapter layers into a sum of kronecker products that can be expressed with a much smaller number of parameters.
John von Neumann quote warned against the dangers of overparameterized models
-
With four parameters I can fit an elephant, and with five I can make him wiggle his trunk.
John von Neumann
With this motivation in mind, we can see the advantages of finetuning a language model without updating every parameter.
Adapter Background
The adapters approach aims to adapt language models in a parameter efficient fashion by inserting small traininable layers between the layers of a transformer.
- Adapters contain a
down projectionas well as an up projection- bottleneck
- opposite of Transformer FFN which has an intermediate dimension 4x the hidden size
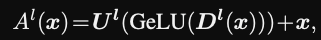
-
Adapter layers are applied in between both the attention and feed forward blocks of a transformer layer
- Compacter’s efficient version of compacter layers are called
parameterized hypercomplex multiplication layers
Kronecker Product Background
- Kronecker product can be considered a generalization of an
outer product- outer product of two vectors is a rank 1 matrix
- Kronecker product of two matrices is a large matrix
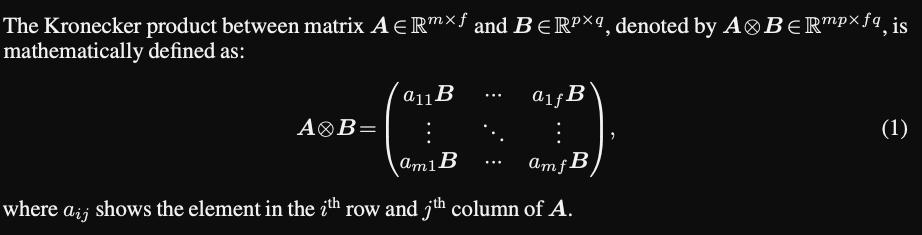
- Kronecker product is also known as the
matrix directproduct- is bilinear and associative
-
In a parameterized hypercomplex multiplication layer the weight matrix is a sum of
kronecker products$W = \sum_{i= 0}^n A_i \otimes B_i$
Parameter complexity is $O(kd/n)$
reduces parameters by factor $\frac{1}{n}$
- In Compacter the adapter weights are a product of
shared task specific parameters and adapter layer specific parameters- Factor both up and down projection weights
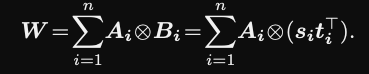
- What two techniques does the compacter paper introduce to make hypercomplex adapters more efficient?
- shared information across adapters
- low rank parameterization
- Reduces complexity to O(k + d)
-
Low rank parameterization is achieved in hypercomplex adapters by
restricting B to be of rank 1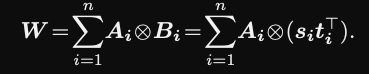
-
Compacter base model is
T5 base220m parameters
The paper compares to several baselines of other parameter efficient adapter approaches:
- Parameter efficient adapter baselines
- Pffeifer adapter: only one adapter in each layer
- Adapter Low Rank
- Prompt tuning
- freeze model and train only continuous prompt token embeddings
- Intrinsic SAID
- Adapter Drop
- drop adapters from lower transformer layers
- Bitfit freeze weights + train only biases
Conclusion
This was a very interesting paper with good results. It’s impressive that language models with a large number of parameters can be adapted successfully with a much smaller number of parameters. Expressing a weight matrix as a sum of kronecker products is an different approach to simple matrix factorization in methods such as ALBERT and seems to work well empirically. I’m excited about the this research direction because practical applications of NLP are often limited by the storage requirements of large models. However, I’m slightly concerned that adapter approaches, while conceptually very simple have a bit of an implementation overhead compared to more intuitive prompt tuning approaches.
Reference
@article{mahabadi2021compacter,
title={Compacter: Efficient Low-Rank Hypercomplex Adapter Layers },
author={Rabeeh Karimi Mahabadi and James Henderson and Sebastian Ruder },
year={2021},
journal={arXiv preprint arXiv: Arxiv-2106.04647}
}