
Combining Compressions for Multiplicative Size Scaling on Natural
Type: Paper
Introduction
-
What is the name of the unified quantization and distillation paper?
Combining Compressions for Multiplicative Size Scaling on Natural Language Tasks
Rajiv Movva123 , Jinhao Lei2 , Shayne Longpre23 , Ajay Gupta2 , and Chris DuBois
-
What are the main contribution of the Combining Compressions paper?
- Compare KD, QAT and MP
- QAT has the best accuracy compression tradeoffs
- Few diminishing returns when combining methods
- QAT and KD amplify accuracy losses when used together
Method
- Magnitude pruning masks the weights with
lowest magnitudesto achieve a target sparsity- we iteratively prune weights at a linear schedule during training after some warmup steps.
- How does this affect training/inference speed
- Combining Compression QAT is done with
int8weights - Pruning embedding weights seems to
significantly harm accuracy - Combining Compression experiment applies
data augmentationalong with knowledge distillation- train student for 3 epochs
- synonym replacement augmentation
- What sizes of BERT models does combining compressions evaluate?
- LARGE (367 million params),
- BASE (134M),
- MEDIUM (57M),
- SMALL (45M),
- MINI (19M),
- TINY (8M).
Results
-
Combining Compression results:
all three techniques togetheryields the best results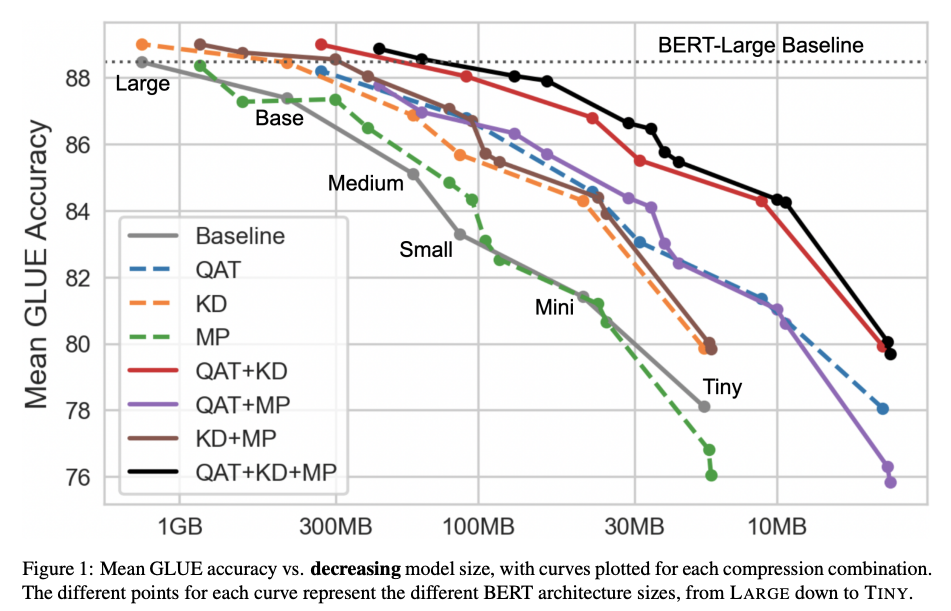
-
Combining Compression results: maximum decreases in size while
maintaining accuracy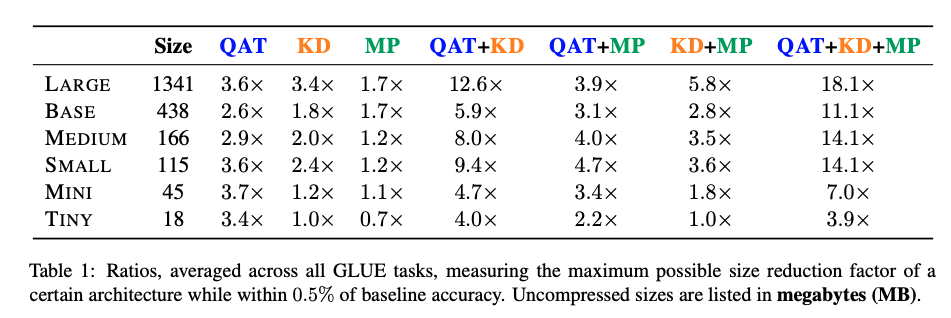
Conclusions
It would have been interesting to include some additional baseline experiments, especially benchmarking the inference speed of models trained with each method. Given that inference is generally a larger concern for models at this scale than model size, I would have started with this experiment. It would also be interesting to compare int8 QAT to int16 versions and post hoc quantization methods
Reference
@misc{movva2022combining,
title={Combining Compressions for Multiplicative Size Scaling on Natural Language Tasks},
author={Rajiv Movva and Jinhao Lei and Shayne Longpre and Ajay Gupta and Chris DuBois},
year={2022},
eprint={2208.09684},
archivePrefix={arXiv},
primaryClass={cs.CL}
}