
CDLM: Cross-Document Language Model
Introduction
-
What is the name of the CDLM paper?
CDLM: Cross-Document Language Modeling
AI2
- What are the main contributions of the CDLM paper?
- multidocument pretraining tasks
- dynamic global attention pattern
- SOTA for some multidocument tasks
- Why is dealing with multiple texts important in NLP?
- cross document coreference resolution
- classifying relations between document pairs
- multihop question answering
Method
-
CDLM two main ideas are
multidocument pretraining and dynamic longformer global attention -
CDLM can handle any number of documents that
fit into longformer context window (4096 tokens) -
Longformer attention patterns
global + sliding window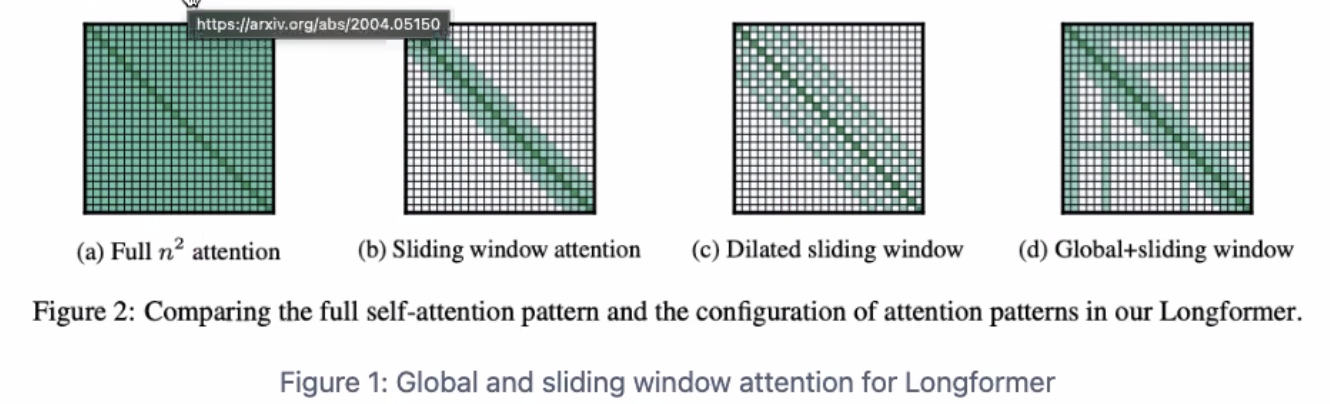
-
Longformer applies global attention to
manually specified tokens - CDLM pretrains on document clusters from the
multinews dataset- dataset originally intended for multidocument summarization
- CDLM pretraining input is
concatenated related documents- use special document separator tokens
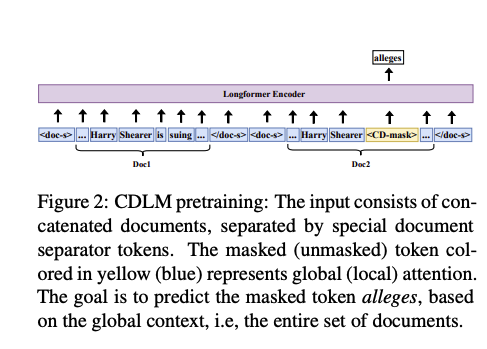
-
CDLM pretraining: masked token is allowed to
attend to full global sequence -
CDLM ablations: prefix CDLM is
BigBird style global attention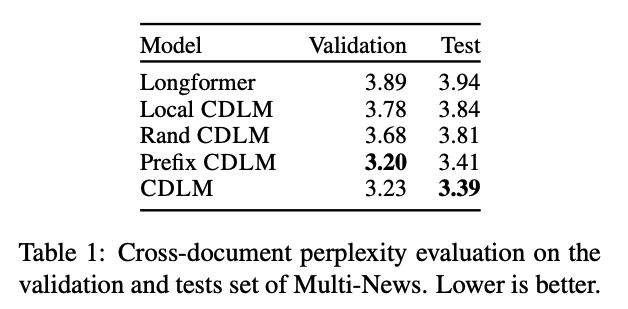
Results
-
CDLM results: strong results on
Cross Document Coreference Resolution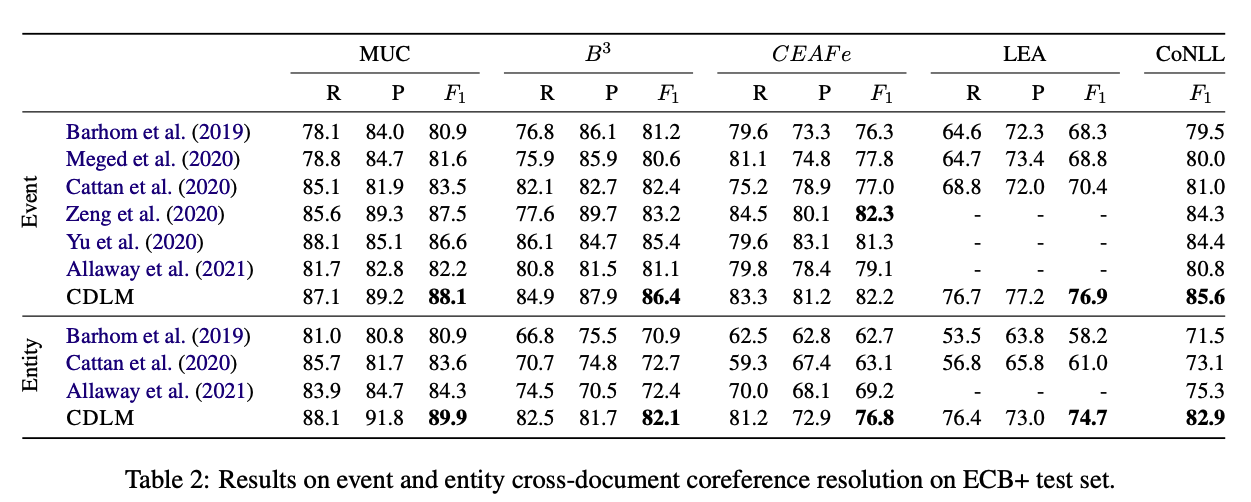
- also performs well on document matching tasks
Conclusions
This paper explores a simple method to train language models for document understanding. They leverage the long former backbone model to make use of extended context length.
Reference
@article{caciularu2021cdlm,
title = {CDLM: Cross-Document Language Modeling},
author = {Avi Caciularu and Arman Cohan and Iz Beltagy and Matthew E. Peters and Arie Cattan and Ido Dagan},
year = {2021},
journal = {arXiv preprint arXiv: Arxiv-2101.00406}
}