
A Structural Probe for Finding Syntax in Word Representations
Introduction
-
What is the name of the NLP structural probe paper?
A Structural Probe for Finding Syntax in Word Representations
John Hewitt, Christopher Manning, Stanford
- What are the main contributions of the NLP structural probes paper?
- evaluate whether a structural probe can transform vectors into a space where squared L2 distance corresponds to number of edges between words in a parse tree
- Show that BERT embeds these trees with high consistency
- What is a motivation for learning a linear transformation of BERT embeddings for structural probes?
- neural network may only embed parse trees in part of the vector
- transformation allows for finding the part of the representation space that is used to encode syntax
- note this is highly related to the residual subspaces explored in the anthropic circuits paper
- NLP structural probe training objective for parse tree distance of words
- train probe to map embeddings to space where inner product matches parse tree distance
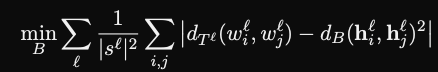
-
The parse depth of a word is the
number of edges between word and root$ w_i $ - Probes can also be designed to test for
tree parse depth
Results
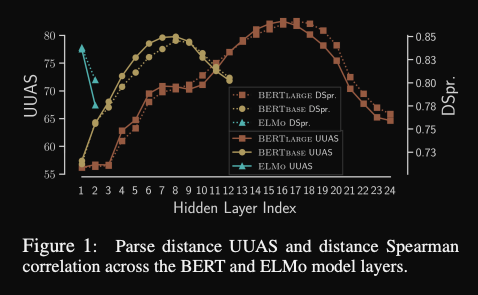
- Structural probing results: different BERT layers encode
different details of syntactic information- overall predictive power is high indicating that BERT can indeed learn some syntax
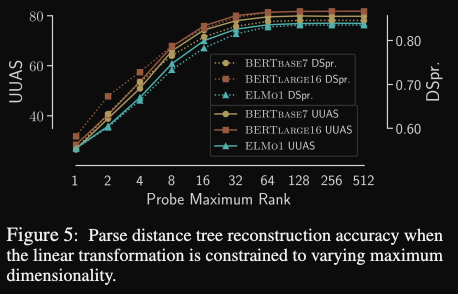
- Structural probe increasing rank levels off of performance indicating that
syntactic information is preserved in a lower dimensional subspace of a representation vector- it would be interesting to analyze precisely which part of the subspace this was (ie which vector dimensions have high coefficient in the linear transformation matrix)
Conclusions
This paper uses a method almost identical to the Visualizing and Measuring the Geometry of BERT to analyze syntactic structure in language model embedding spaces. The analysis of the maximum rank of the probes was the most significant addition of this paper. Such probing methods can easily be applied to new language models. As mentioned earlier, it would be interesting to apply ideas from the Anthropic transformer circuits series of papers in order to see how syntactic information is encoded in small dimension of the vector representation space and how it might evolve while passing through the residual stream.
Reference
https://nlp.stanford.edu/pubs/hewitt2019structural.pdf