
1 Year of a Challenging Big-Bench Task
In 2021 I contributed to the Big-Bench suite of NLP tasks, aiming to probe the abilities of large language models. Inspired by sports, I developed a task aiming to test the world knowledge and reasoning ability of large language models. Given that a little over a year later, the task has essentially been solved I decided to summarize the progress and interesting developments for this specific task.
The task itself asks participants to determine if a sentence about sports is plausible or implausible: For example, given the sentence:
Tom Brady made a layup in the NBA Final
The answer is “implausible” because Tom Brady is a football player and would not be making a basketball play in a basketball game.
The human performance on the task is primarily driven by accumulated world knowledge about sports. Human participants had zero difficulties grasping the aim of the task and the need to match players to their respective sports. However given the breadth of examples, most participants were not familiar with every athlete and sport presented. Therefore the fact that large language models can outperform human benchmarks is not as interesting as the way in which these behaviors emerge
It took just over a year for me to consider the task solved by large language models with the SOTA performance at 98% (Sugzun 2022). Initially smaller LMs performed no better than random in both the few shot and zero-shot regimes. However, we can track the ultimate cracking of the task through model scale and prompting techniques.
This plot from Wei et al shows the error rate on the task as a function of model compute in FLOPs for google’s Lambda model. We can see a definite inflection point in terms of emergent behavior
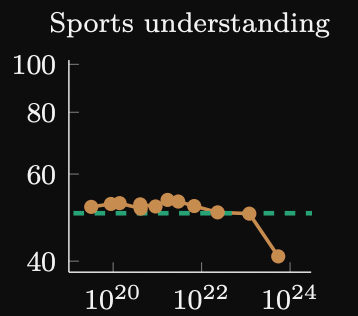
It appears that solving the task is an emergent ability of large language models. The paper classifies sports understanding as emergent for GPT-3 and Lambda meaning that performance on this task appears to be suddenly emergent at this regime of model size. I believe that this is somewhat surprising given that the task is not particularly complicated and should be solvable few shot by smaller models. However, we will see that a combination of model scale and better prompting techniques are essential to solve the task.
The task is explicitly designed to test a two-step logical reasoning process: From the above example the language model should be able to reason from the implications Tom Brady plays football and basketball players make layups → Tom Brady making a layup is less plausible. The development of Chain of Thought prompting gives language models this exact ability. We can construct the modified COT prompts very easily:

Which immediately results in a dramatic performance gain:
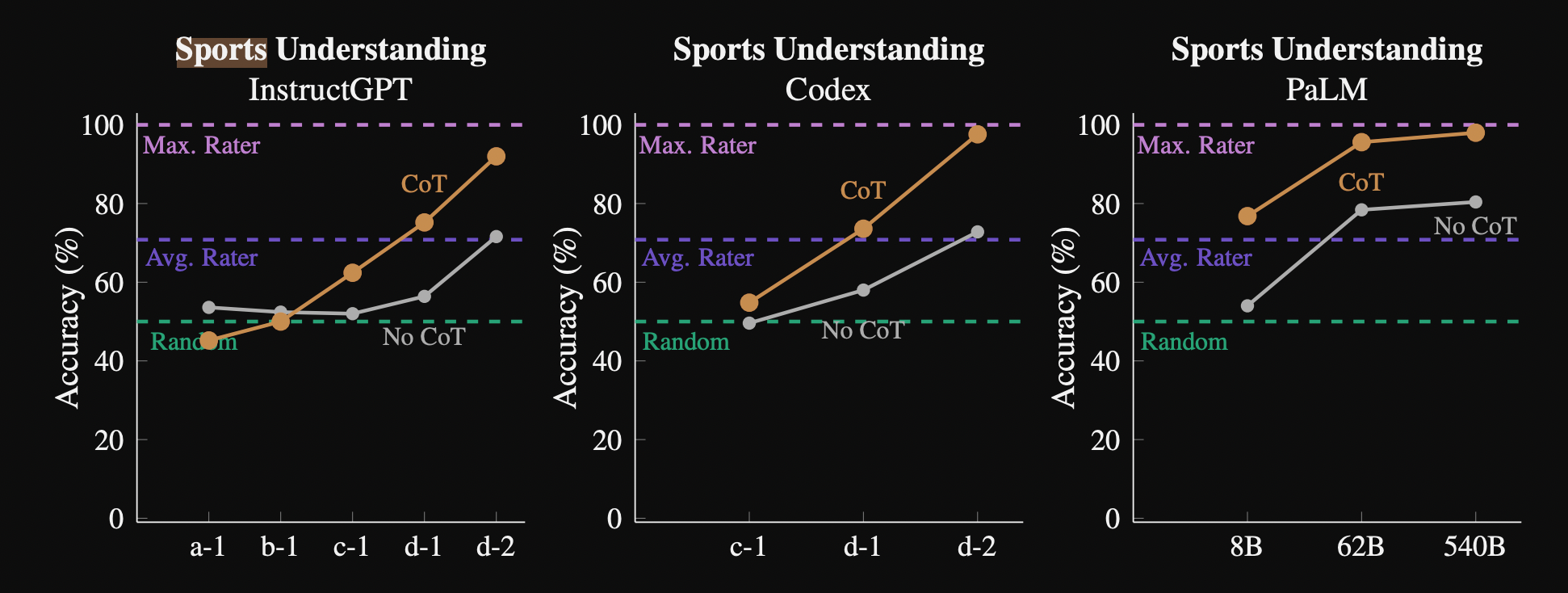
Interestingly, with Chain of Thought prompting, even smaller models (8B) parameters are able to reach human-level performance. In addition, we see the emergence of behavior at smaller model scales (OpenAi -curie vs davinci).
It’s an interesting question as to whether performance at scale is driven by more world knowledge memorization capabilities vs reasoning capabilities. Given that we know that all PALM variants were trained on the same data we can speculate about the relative contributions. At 8Billion parameters, PALM does little better than random however with Chain of Thought prompting performance improves dramatically. This illustrates how Chain of Thought prompting elucidates latent world knowledge already present in the 8Billion parameter model. However it’s possible that the smaller-scale PALM model did not have the capacity to pick up on all of the world knowledge needed to solve the task in the single epoch training. Assuming a lot of sports understanding relevant data comes from New articles, we can see that two larger PALM variants memorize training the training data to approximately the same degree.
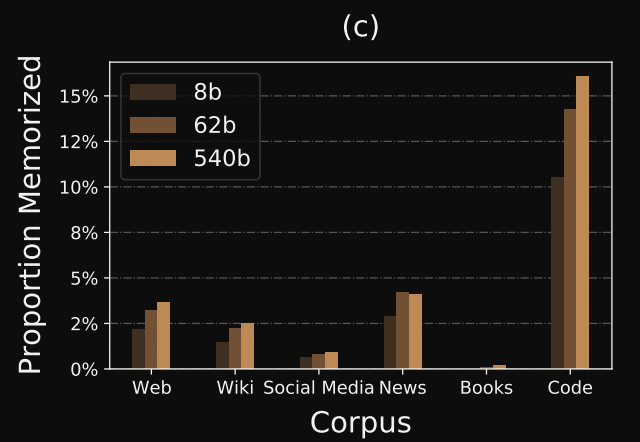
Given this fact we can theorize that the gains from 62B to 540B parameters are driven mostly by improved reasoning ability while gains from 8B to 62B may also be a factor of world knowledge. I believe this hypothesis could be rigorously evaluated by thoroughly probing the models for the necessary factual knowledge for each task. Then we can correlate the degree of task-relevant world knowledge with task performance. Such experiments could explain why some other tasks requiring world knowledge failed to demonstrate improvement with COT prompting.
References
@misc{srivastava_beyond_2022,
title = {Beyond the {Imitation} {Game}: {Quantifying} and extrapolating the capabilities of language models},
shorttitle = {Beyond the {Imitation} {Game}},
url = {http://arxiv.org/abs/2206.04615},
abstract = {Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.},
urldate = {2023-01-07},
publisher = {arXiv},
author = {Srivastava, Aarohi and Rastogi, Abhinav and Rao, Abhishek and Shoeb, Abu Awal Md and Abid, Abubakar and Fisch, Adam and Brown, Adam R. and Santoro, Adam and Gupta, Aditya and Garriga-Alonso, Adrià and Kluska, Agnieszka and Lewkowycz, Aitor and Agarwal, Akshat and Power, Alethea and Ray, Alex and Warstadt, Alex and Kocurek, Alexander W. and Safaya, Ali and Tazarv, Ali and Xiang, Alice and Parrish, Alicia and Nie, Allen and Hussain, Aman and Askell, Amanda and Dsouza, Amanda and Slone, Ambrose and Rahane, Ameet and Iyer, Anantharaman S. and Andreassen, Anders and Madotto, Andrea and Santilli, Andrea and Stuhlmüller, Andreas and Dai, Andrew and La, Andrew and Lampinen, Andrew and Zou, Andy and Jiang, Angela and Chen, Angelica and Vuong, Anh and Gupta, Animesh and Gottardi, Anna and Norelli, Antonio and Venkatesh, Anu and Gholamidavoodi, Arash and Tabassum, Arfa and Menezes, Arul and Kirubarajan, Arun and Mullokandov, Asher and Sabharwal, Ashish and Herrick, Austin and Efrat, Avia and Erdem, Aykut and Karakaş, Ayla and Roberts, B. Ryan and Loe, Bao Sheng and Zoph, Barret and Bojanowski, Bartłomiej and Özyurt, Batuhan and Hedayatnia, Behnam and Neyshabur, Behnam and Inden, Benjamin and Stein, Benno and Ekmekci, Berk and Lin, Bill Yuchen and Howald, Blake and Diao, Cameron and Dour, Cameron and Stinson, Catherine and Argueta, Cedrick and Ramírez, César Ferri and Singh, Chandan and Rathkopf, Charles and Meng, Chenlin and Baral, Chitta and Wu, Chiyu and Callison-Burch, Chris and Waites, Chris and Voigt, Christian and Manning, Christopher D. and Potts, Christopher and Ramirez, Cindy and Rivera, Clara E. and Siro, Clemencia and Raffel, Colin and Ashcraft, Courtney and Garbacea, Cristina and Sileo, Damien and Garrette, Dan and Hendrycks, Dan and Kilman, Dan and Roth, Dan and Freeman, Daniel and Khashabi, Daniel and Levy, Daniel and González, Daniel Moseguí and Perszyk, Danielle and Hernandez, Danny and Chen, Danqi and Ippolito, Daphne and Gilboa, Dar and Dohan, David and Drakard, David and Jurgens, David and Datta, Debajyoti and Ganguli, Deep and Emelin, Denis and Kleyko, Denis and Yuret, Deniz and Chen, Derek and Tam, Derek and Hupkes, Dieuwke and Misra, Diganta and Buzan, Dilyar and Mollo, Dimitri Coelho and Yang, Diyi and Lee, Dong-Ho and Shutova, Ekaterina and Cubuk, Ekin Dogus and Segal, Elad and Hagerman, Eleanor and Barnes, Elizabeth and Donoway, Elizabeth and Pavlick, Ellie and Rodola, Emanuele and Lam, Emma and Chu, Eric and Tang, Eric and Erdem, Erkut and Chang, Ernie and Chi, Ethan A. and Dyer, Ethan and Jerzak, Ethan and Kim, Ethan and Manyasi, Eunice Engefu and Zheltonozhskii, Evgenii and Xia, Fanyue and Siar, Fatemeh and Martínez-Plumed, Fernando and Happé, Francesca and Chollet, Francois and Rong, Frieda and Mishra, Gaurav and Winata, Genta Indra and de Melo, Gerard and Kruszewski, Germán and Parascandolo, Giambattista and Mariani, Giorgio and Wang, Gloria and Jaimovitch-López, Gonzalo and Betz, Gregor and Gur-Ari, Guy and Galijasevic, Hana and Kim, Hannah and Rashkin, Hannah and Hajishirzi, Hannaneh and Mehta, Harsh and Bogar, Hayden and Shevlin, Henry and Schütze, Hinrich and Yakura, Hiromu and Zhang, Hongming and Wong, Hugh Mee and Ng, Ian and Noble, Isaac and Jumelet, Jaap and Geissinger, Jack and Kernion, Jackson and Hilton, Jacob and Lee, Jaehoon and Fisac, Jaime Fernández and Simon, James B. and Koppel, James and Zheng, James and Zou, James and Kocoń, Jan and Thompson, Jana and Kaplan, Jared and Radom, Jarema and Sohl-Dickstein, Jascha and Phang, Jason and Wei, Jason and Yosinski, Jason and Novikova, Jekaterina and Bosscher, Jelle and Marsh, Jennifer and Kim, Jeremy and Taal, Jeroen and Engel, Jesse and Alabi, Jesujoba and Xu, Jiacheng and Song, Jiaming and Tang, Jillian and Waweru, Joan and Burden, John and Miller, John and Balis, John U. and Berant, Jonathan and Frohberg, Jörg and Rozen, Jos and Hernandez-Orallo, Jose and Boudeman, Joseph and Jones, Joseph and Tenenbaum, Joshua B. and Rule, Joshua S. and Chua, Joyce and Kanclerz, Kamil and Livescu, Karen and Krauth, Karl and Gopalakrishnan, Karthik and Ignatyeva, Katerina and Markert, Katja and Dhole, Kaustubh D. and Gimpel, Kevin and Omondi, Kevin and Mathewson, Kory and Chiafullo, Kristen and Shkaruta, Ksenia and Shridhar, Kumar and McDonell, Kyle and Richardson, Kyle and Reynolds, Laria and Gao, Leo and Zhang, Li and Dugan, Liam and Qin, Lianhui and Contreras-Ochando, Lidia and Morency, Louis-Philippe and Moschella, Luca and Lam, Lucas and Noble, Lucy and Schmidt, Ludwig and He, Luheng and Colón, Luis Oliveros and Metz, Luke and Şenel, Lütfi Kerem and Bosma, Maarten and Sap, Maarten and ter Hoeve, Maartje and Farooqi, Maheen and Faruqui, Manaal and Mazeika, Mantas and Baturan, Marco and Marelli, Marco and Maru, Marco and Quintana, Maria Jose Ramírez and Tolkiehn, Marie and Giulianelli, Mario and Lewis, Martha and Potthast, Martin and Leavitt, Matthew L. and Hagen, Matthias and Schubert, Mátyás and Baitemirova, Medina Orduna and Arnaud, Melody and McElrath, Melvin and Yee, Michael A. and Cohen, Michael and Gu, Michael and Ivanitskiy, Michael and Starritt, Michael and Strube, Michael and Swędrowski, Michał and Bevilacqua, Michele and Yasunaga, Michihiro and Kale, Mihir and Cain, Mike and Xu, Mimee and Suzgun, Mirac and Tiwari, Mo and Bansal, Mohit and Aminnaseri, Moin and Geva, Mor and Gheini, Mozhdeh and T, Mukund Varma and Peng, Nanyun and Chi, Nathan and Lee, Nayeon and Krakover, Neta Gur-Ari and Cameron, Nicholas and Roberts, Nicholas and Doiron, Nick and Nangia, Nikita and Deckers, Niklas and Muennighoff, Niklas and Keskar, Nitish Shirish and Iyer, Niveditha S. and Constant, Noah and Fiedel, Noah and Wen, Nuan and Zhang, Oliver and Agha, Omar and Elbaghdadi, Omar and Levy, Omer and Evans, Owain and Casares, Pablo Antonio Moreno and Doshi, Parth and Fung, Pascale and Liang, Paul Pu and Vicol, Paul and Alipoormolabashi, Pegah and Liao, Peiyuan and Liang, Percy and Chang, Peter and Eckersley, Peter and Htut, Phu Mon and Hwang, Pinyu and Miłkowski, Piotr and Patil, Piyush and Pezeshkpour, Pouya and Oli, Priti and Mei, Qiaozhu and Lyu, Qing and Chen, Qinlang and Banjade, Rabin and Rudolph, Rachel Etta and Gabriel, Raefer and Habacker, Rahel and Delgado, Ramón Risco and Millière, Raphaël and Garg, Rhythm and Barnes, Richard and Saurous, Rif A. and Arakawa, Riku and Raymaekers, Robbe and Frank, Robert and Sikand, Rohan and Novak, Roman and Sitelew, Roman and LeBras, Ronan and Liu, Rosanne and Jacobs, Rowan and Zhang, Rui and Salakhutdinov, Ruslan and Chi, Ryan and Lee, Ryan and Stovall, Ryan and Teehan, Ryan and Yang, Rylan and Singh, Sahib and Mohammad, Saif M. and Anand, Sajant and Dillavou, Sam and Shleifer, Sam and Wiseman, Sam and Gruetter, Samuel and Bowman, Samuel R. and Schoenholz, Samuel S. and Han, Sanghyun and Kwatra, Sanjeev and Rous, Sarah A. and Ghazarian, Sarik and Ghosh, Sayan and Casey, Sean and Bischoff, Sebastian and Gehrmann, Sebastian and Schuster, Sebastian and Sadeghi, Sepideh and Hamdan, Shadi and Zhou, Sharon and Srivastava, Shashank and Shi, Sherry and Singh, Shikhar and Asaadi, Shima and Gu, Shixiang Shane and Pachchigar, Shubh and Toshniwal, Shubham and Upadhyay, Shyam and Shyamolima and Debnath and Shakeri, Siamak and Thormeyer, Simon and Melzi, Simone and Reddy, Siva and Makini, Sneha Priscilla and Lee, Soo-Hwan and Torene, Spencer and Hatwar, Sriharsha and Dehaene, Stanislas and Divic, Stefan and Ermon, Stefano and Biderman, Stella and Lin, Stephanie and Prasad, Stephen and Piantadosi, Steven T. and Shieber, Stuart M. and Misherghi, Summer and Kiritchenko, Svetlana and Mishra, Swaroop and Linzen, Tal and Schuster, Tal and Li, Tao and Yu, Tao and Ali, Tariq and Hashimoto, Tatsu and Wu, Te-Lin and Desbordes, Théo and Rothschild, Theodore and Phan, Thomas and Wang, Tianle and Nkinyili, Tiberius and Schick, Timo and Kornev, Timofei and Telleen-Lawton, Timothy and Tunduny, Titus and Gerstenberg, Tobias and Chang, Trenton and Neeraj, Trishala and Khot, Tushar and Shultz, Tyler and Shaham, Uri and Misra, Vedant and Demberg, Vera and Nyamai, Victoria and Raunak, Vikas and Ramasesh, Vinay and Prabhu, Vinay Uday and Padmakumar, Vishakh and Srikumar, Vivek and Fedus, William and Saunders, William and Zhang, William and Vossen, Wout and Ren, Xiang and Tong, Xiaoyu and Zhao, Xinran and Wu, Xinyi and Shen, Xudong and Yaghoobzadeh, Yadollah and Lakretz, Yair and Song, Yangqiu and Bahri, Yasaman and Choi, Yejin and Yang, Yichi and Hao, Yiding and Chen, Yifu and Belinkov, Yonatan and Hou, Yu and Hou, Yufang and Bai, Yuntao and Seid, Zachary and Zhao, Zhuoye and Wang, Zijian and Wang, Zijie J. and Wang, Zirui and Wu, Ziyi},
month = jun,
year = {2022},
note = {arXiv:2206.04615 [cs, stat]},
keywords = {Computer Science - Artificial Intelligence, Computer Science - Computation and Language, Computer Science - Computers and Society, Computer Science - Machine Learning, Statistics - Machine Learning},
file = {arXiv Fulltext PDF:/Users/ethankim/Zotero/storage/V6L5DYHL/Srivastava et al. - 2022 - Beyond the Imitation Game Quantifying and extrapo.pdf:application/pdf;arXiv.org Snapshot:/Users/ethankim/Zotero/storage/86IGRL9V/2206.html:text/html},
}
@misc{wei_chain_2022,
title = {Chain of {Thought} {Prompting} {Elicits} {Reasoning} in {Large} {Language} {Models}},
url = {http://arxiv.org/abs/2201.11903},
abstract = {We explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models to perform complex reasoning. In particular, we show how such reasoning abilities emerge naturally in sufficiently large language models via a simple method called chain of thought prompting, where a few chain of thought demonstrations are provided as exemplars in prompting. Experiments on three large language models show that chain of thought prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks. The empirical gains can be striking. For instance, prompting a 540B-parameter language model with just eight chain of thought exemplars achieves state of the art accuracy on the GSM8K benchmark of math word problems, surpassing even finetuned GPT-3 with a verifier.},
urldate = {2023-01-08},
publisher = {arXiv},
author = {Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed and Le, Quoc and Zhou, Denny},
month = oct,
year = {2022},
note = {arXiv:2201.11903 [cs]},
keywords = {Computer Science - Artificial Intelligence, Computer Science - Computation and Language},
file = {arXiv Fulltext PDF:/Users/ethankim/Zotero/storage/6M7U2FCV/Wei et al. - 2022 - Chain of Thought Prompting Elicits Reasoning in La.pdf:application/pdf;arXiv.org Snapshot:/Users/ethankim/Zotero/storage/88TQ5JZZ/2201.html:text/html},
}
@misc{suzgun_challenging_2022,
title = {Challenging {BIG}-{Bench} {Tasks} and {Whether} {Chain}-of-{Thought} {Can} {Solve} {Them}},
url = {http://arxiv.org/abs/2210.09261},
abstract = {BIG-Bench (Srivastava et al., 2022) is a diverse evaluation suite that focuses on tasks believed to be beyond the capabilities of current language models. Language models have already made good progress on this benchmark, with the best model in the BIG-Bench paper outperforming average reported human-rater results on 65\% of the BIG-Bench tasks via few-shot prompting. But on what tasks do language models fall short of average human-rater performance, and are those tasks actually unsolvable by current language models? In this work, we focus on a suite of 23 challenging BIG-Bench tasks which we call BIG-Bench Hard (BBH). These are the task for which prior language model evaluations did not outperform the average human-rater. We find that applying chain-of-thought (CoT) prompting to BBH tasks enables PaLM to surpass the average human-rater performance on 10 of the 23 tasks, and Codex (code-davinci-002) to surpass the average human-rater performance on 17 of the 23 tasks. Since many tasks in BBH require multi-step reasoning, few-shot prompting without CoT, as done in the BIG-Bench evaluations (Srivastava et al., 2022), substantially underestimates the best performance and capabilities of language models, which is better captured via CoT prompting. As further analysis, we explore the interaction between CoT and model scale on BBH, finding that CoT enables emergent task performance on several BBH tasks with otherwise flat scaling curves.},
urldate = {2023-01-08},
publisher = {arXiv},
author = {Suzgun, Mirac and Scales, Nathan and Schärli, Nathanael and Gehrmann, Sebastian and Tay, Yi and Chung, Hyung Won and Chowdhery, Aakanksha and Le, Quoc V. and Chi, Ed H. and Zhou, Denny and Wei, Jason},
month = oct,
year = {2022},
note = {arXiv:2210.09261 [cs]},
keywords = {Computer Science - Artificial Intelligence, Computer Science - Computation and Language},
file = {arXiv Fulltext PDF:/Users/ethankim/Zotero/storage/BJC2HH66/Suzgun et al. - 2022 - Challenging BIG-Bench Tasks and Whether Chain-of-T.pdf:application/pdf;arXiv.org Snapshot:/Users/ethankim/Zotero/storage/XAVAF53N/2210.html:text/html},
}
@article{wei_emergent_nodate,
title = {Emergent {Abilities} of {Large} {Language} {Models}},
abstract = {Scaling up language models has been shown to predictably improve performance and sample efficiency on a wide range of downstream tasks. This paper instead discusses an unpredictable phenomenon that we refer to as emergent abilities of large language models. We consider an ability to be emergent if it is not present in smaller models but is present in larger models. Thus, emergent abilities cannot be predicted simply by extrapolating the performance of smaller models. The existence of such emergence raises the question of whether additional scaling could potentially further expand the range of capabilities of language models.},
language = {en},
author = {Wei, Jason and Tay, Yi and Bommasani, Rishi and Raffel, Colin and Zoph, Barret and Borgeaud, Sebastian and Yogatama, Dani and Bosma, Maarten and Zhou, Denny and Metzler, Donald and Chi, Ed H and Hashimoto, Tatsunori and Vinyals, Oriol and Liang, Percy and Dean, Jeff and Fedus, William},
file = {Wei et al. - Emergent Abilities of Large Language Models.pdf:/Users/ethankim/Zotero/storage/6QZFBPBV/Wei et al. - Emergent Abilities of Large Language Models.pdf:application/pdf},
}
@article{chowdhery2022palm,
title={Palm: Scaling language modeling with pathways},
author={Chowdhery, Aakanksha and Narang, Sharan and Devlin, Jacob and Bosma, Maarten and Mishra, Gaurav and Roberts, Adam and Barham, Paul and Chung, Hyung Won and Sutton, Charles and Gehrmann, Sebastian and others},
journal={arXiv preprint arXiv:2204.02311},
year={2022}
}